在学习 Unix 的进程管理的时候,尝试实现过一个 shell,当然写这种程序的目的不是为了挑战、替代当前市面上流行的 shell 程序。 主要是通过对 shell 程序的编写,去理解 Unix 系统为我们提供了哪些功能,通过什么机制来处理我们的程序,如何更好的在这个系统上工作。
编写过程中对于管道的处理中有不少感悟,记录与诸君共赏。
shell 原理
众所周知,shell 程序原理很简单,对于大多数功能,启动一个进程,等待用户输入,读取输入内容,解析后丢给子进程去执行,基本就可以了。
当然,实现起来还是会有很多细节需要去注意,比如,用户输入太长怎么办?命令有几个参数该怎么办?
比如程序设置的缓冲区是 1000 个字节,读取超过 1000 个字节,是不是需要扩容一倍,复制过去,释放掉原来的,继续读取?
在写程序初期,一定要记住一个原理,要抓住主要矛盾。比如我就规定死,最多只读取 1000 字节,超出部分我就不处理了。
我们的目的是通过这个练习来熟悉 Unix 系统,不要陷入这无尽的细节中去。
这些决策其实也体现在我们日常的工作生活中,这也是一种练习,出问题的时候我们该怎样去做这样的决策。这决定着你是 6 点准时下班,还是加班到 10 点:) 。
回归正题,我们想要实现管道,它长这样,通过 | 把上一个命令的输出,作为下一个命令的输入。就像下面这样:
➜ /tmp echo xiecang.cc | cat
xiecang.cc为了实现它,我们需要使用到 dup 和 pipe 这两个命令,下面来简单介绍下这两个命令是做什么的。
dup
dup 是一个系统调用,用于复制文件描述符,新的描述符将指向相同的文件。我们可以用新旧描述符访问到同一个文件。
DUP(2) System Calls Manual DUP(2)
NAME
dup, dup2 – duplicate an existing file descriptor
SYNOPSIS
#include <unistd.h>
int
dup(int fildes);
int
dup2(int fildes, int fildes2);我们知道,一个进程启动后,一般会默认打开三个文件描述符,依次是标准输入 0,标准输出 1,标准错误输出 2。 后续如果我们还想继续打开文件,它的 fileId 会依次递增,3,4,5…。
同时,Unix 系统还有另一个特性,如果你关闭了某个已经打开的文件描述符,这个文件描述符 fileId 会被在下一次打开的时候被重用。 也就是说,你打开了文件 fileId 为 3,然后关闭它,打开一个新文件,fileId 还会是 3。 同理,关闭了 fileId 0,打开的新的文件 fileId 是 0。
你可能写过不少程序,也许会认为这种设计就是一个 bug, 应该递增呀,怎么还能复用的。但是很不幸,它就这么设计了,而且 Unix 世界需要依赖这个 bug 去以一种比较怪异的方式实现管道 :(
让我们来看这个程序:
int
OSdup() {
system("echo www.xiecang.cc > cc.1");
system("pwd; ls -l");
int fileId = open("cc.1", O_RDWR);
// STDIN_FILENO = 0
close(STDIN_FILENO);
int newId = dup(fileId);
printf("new id (%d)\n", newId);
//
int size = 10;
char buffer[size];
read(STDIN_FILENO, buffer, size);
printf("(%s)\n", buffer);
return 0;
}它创建了一个文件,cc.1,调用 ls -l 可以看到确实存在这个文件,
然后打开它,此时 fileId = 3,然后 close 标准输入 0,
dup 一下描述符 fileId
由 dup 调用的特性可知 newId 会和 fileId 都指向同一个文件 cc.1,读它就是读 cc.1, 写它也是写 cc.1,
同时,根据我们上面介绍的 bug 特性可知,我们关闭标准输入 0,新打开的文件(dup 后的)描述符,会重用标准输入 0,所以 newId =
0,
有趣的来了,我们从标准输入STDIN_FILENO(0) 里面读取内容,其实就是从 cc.1 中读取,于是 buffer 中读到的内容,就是 cc.1
里的内容。
记住这个 dup,它很重要,我们后面会用到,下面我们来看看另一个命令 pipe。
pipe
什么是管道?
上一个进程的输出变成下一个进程的输入。
其实 dup 就可以用来实现管道,下一个进程本来是从 stdin 标准输入中的读,把它关掉,把它的标准输入替换一下,它就变成从其它地方读了,我们就不展开了,Unix
系统为我们提供了创建管道的命令 pipe。
PIPE(2) System Calls Manual PIPE(2)
NAME
pipe – create descriptor pair for interprocess communication
SYNOPSIS
#include <unistd.h>
int
pipe(int fildes[2]);下面这个程序,创建了一个管道后 fork,父进程写,子进程读,
int
OSPipe() {
int fileIds[2];
pipe(fileIds);
printf("pipe (%d), (%d)\n", fileIds[0], fileIds[1]);
pid_t pid = fork();
if (pid == 0) {
char buffer[10];
read(fileIds[0], buffer, 3);
//
write(1, buffer, 3);
write(1, "\n", 1);
// printf("%s\n", buffer);
} else {
write(fileIds[1], "acc", 3);
}
// wait(&pid);
return 0;
}往 fileIds[1] 中写,可以从 fileIds[0] 中读到,可以看到子进程会打印出父进程写的内容。
➜ cc main.c -o unix && ./unix
pipe (3), (4)
acc使用起来很简单对吧?是的,pipe 的功能就是这些。但是我们的 shell 管道的正确执行,还需要用到 fork 中的一个设定,稍微花点篇幅来介绍一下。
fork 的设定
前面介绍到:
一个进程启动后,一般会默认打开三个文件描述符,依次是标准输入 0,标准输出 1,标准错误输出 2。
在 fork 命令创建后,会产生一个子进程,那么子进程的标准输入,标准输入和标准错误输入怎么办呢?
答案是,子进程的输入输出和父进程是共享的。
来看这个例子:
int
OSFork() {
pid_t pid = fork();
if (pid == 0) {
printf("child: ");
char c;
// 从标准输入中读一个字节
read(STDIN_FILENO, &c, 1);
// 往标准输出中写刚刚读到的内容
write(STDOUT_FILENO, &c, 1);
printf("\n");
} else {
printf("parent: ");
char c;
// 从标准输入中读一个字节
read(STDIN_FILENO, &c, 1);
// 往标准输出中写刚刚读到的内容
write(STDOUT_FILENO, &c, 1);
printf("\n");
}
return 0;
}子进程和父进程分别从标准输入中读取一字节,然后写入到标准输出,输入 12 child 和 parent 分别读到 1,2
正式由于这种级别的共享,所以刚刚管道的示例中,fork 前创建的管道,是被父子进程共享的,是同一个。
shell 管道的实现
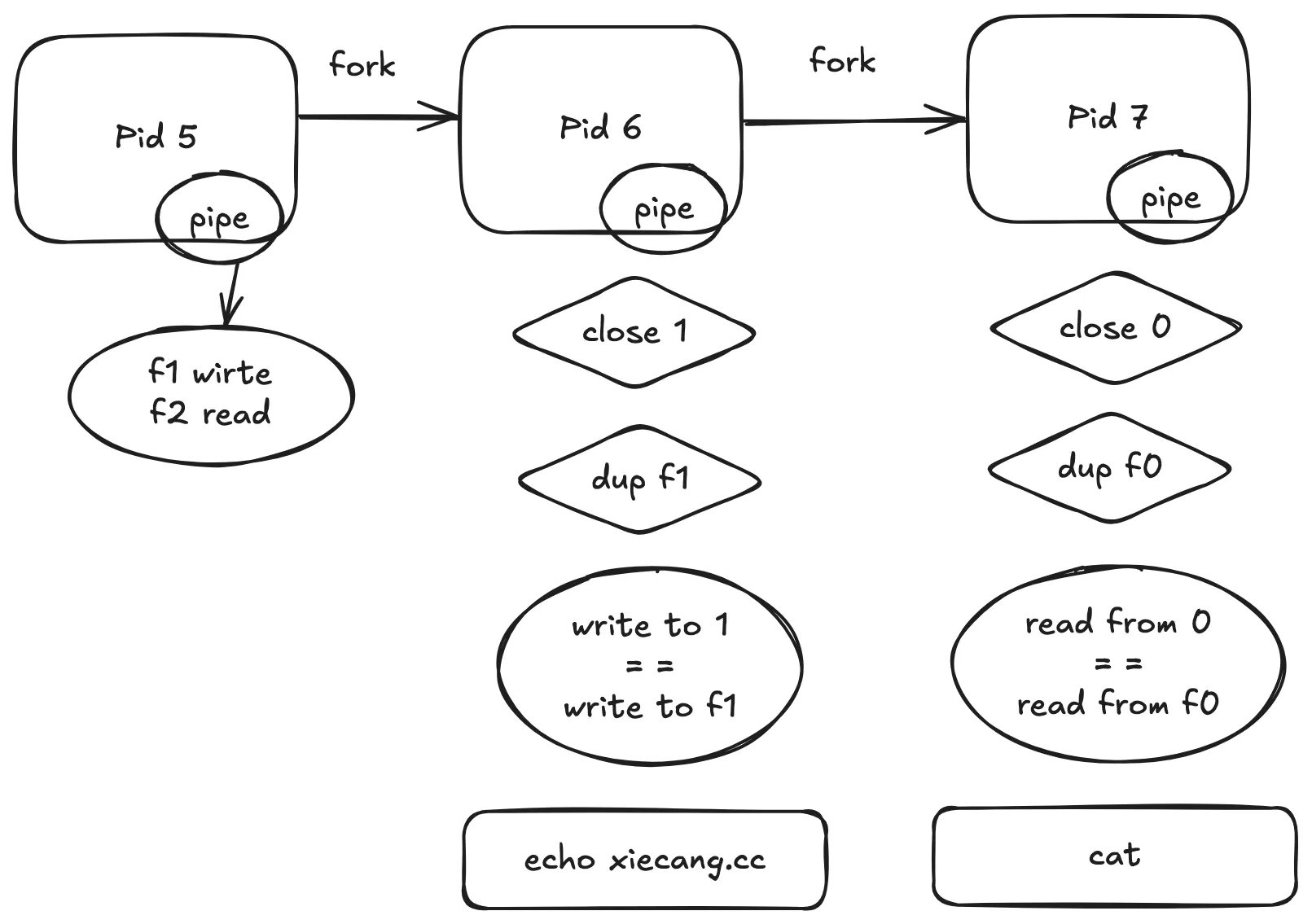
- 假设当前进程 pid 是 5
- 先创建一个管道 pipe, 前面可以知道往
fileIds[1]中写,可以从fileIds[0]中读到 - 然后我们执行 fork,得到子进程 pid 是 6
- pid 6 再 fork 一次(或者 pid 5 再 fork 一次,都一样),得到进程 pid 7
- 这样,进程 pid 5、6、7 就共享了同一个管道
- 我们把进程 6 的 1(标准输出)关闭
- 把 pid 7 的 0 (标准输入) 关闭
- 在进程 6 中 dup 写文件的管道(
fileIds[1]),这样这个进程往1(标准输出)写,就会写入到管道中(dup 复制的时候,得到的 id 就是刚刚关闭的 1, 1 就等同于 fileIds[1] ) - 在进程 7 中,把读文件的管道(
fileIds[0])复制一下 , 此时 0 (标准输入) 就等同于fileIds[0],从标准输入中读取,就相当于从管道中读取
| 前后两个命令,分别在 6 号进程和 7 号进程中执行,就相当于把左边的输出,传给了右边的输出。
总结
本文介绍了实现 shell 管道用到的两个命令 dup 和 pipe,利用 fork 资源的共享,创建的子进程共用了同一个管道
并且根据关闭描述符,dup 后会重用关闭的描述符特性,我们让标准输出/输入和管道的输入/输出进行了关联,
从而实现,在前一个进程的输出,会输出到管道的写入端,另一个进程从标准输入中读取,相当于从管道中读取。
从而实现了管道的功能 —— 前一个程序的输出,作为后一个进程的输入。