- OpenResty 学习笔记(目录)
- OpenResty 学习笔记(2) - 前置知识
- OpenResty 学习笔记(3) - LuaJIT
- OpenResty 学习笔记(4) - OpenResty 原理和 API
- OpenResty 学习笔记(5) - shared dict、cosocket、特权进程
- OpenResty 学习笔记(6) - 测试工具
- OpenResty 学习笔记(7) - 性能优化和编码指南
- OpenResty 学习笔记(8) - 动态调试
目录
性能优化
阻塞函数
回顾 OpenResty 高性能的关键:
- 在遇到网络 I/O 等需要等待返回才能继续的操作时,就会先调用 Lua 协程的 yield 把自己挂起,然后在 Nginx 中注册回调;
- 在 I/O 操作完成(也可能是超时或者出错)后,由 Nginx 回调 resume,来唤醒 Lua 协程。
执行阻塞函数时 LuaJIT 不会把控制权交给 Nginx 的事件循环,导致其它请求需要排队等候。
执行外部命令
os.execute("openssl genrsa -des3 -out private.pem 2048 ")os.execute 是 Lua 的内置函数,会阻塞当前请求。
方案一:使用 FFI 的方式来调用
比如上面可以用 FFI 库 lua-resty-signal
local resty_signal = require "resty.signal"
local pid = 12345
local ok, err = resty_signal.kill(pid, "KILL")方案二:使用基于 ngx.pipe 的 lua-resty-shell 库。
$ resty -e 'local shell = require "resty.shell"
local ok, stdout, stderr, reason, status =
shell.run([[echo "hello, world"]])
ngx.say(stdout) '磁盘 I/O
local path = "/conf/apisix.conf"
local file = io.open(path, "rb")
local content = file:read("*a")
file:close()这段代码使用 io.open ,来获取某个文件中的所有内容。如果在 init 和 init worker 中调用,那么它其实是个一次性的动作,并没有影响任何终端用户的请求,是完全可以被接受的。
第一种方式,我们可以使用 lua-io-nginx-module 这个第三方的 C 模块。它为 OpenResty 提供了“非阻塞”的 Lua API,不过,这里的非阻塞是加了引号的,你不能像 cosocket 一样,随心所欲地去使用它。因为磁盘的 I/O 消耗并不会平白无故地消失,只不过是换了一种方式而已。
这种方式的原理是,lua-io-nginx-module 利用了 Nginx 的线程池,把磁盘 I/O 操作从主线程转移到另外一个线程中处理,这样,主线程就不会因为磁盘 I/O 操作而被阻塞。
使用这个库时,你需要重新编译 Nginx。
local ngx_io = require "ngx.io"
local path = "/conf/apisix.conf"
local file, err = ngx_io.open(path, "rb")
local data, err = file: read("*a")
file:close()第二种方式,则是尝试架构上的调整。
比如在本地磁盘中记录日志,修改为把日志发送到远端的日志服务器上,这样就可以用 cosocket 来完成非阻塞的网络通信了,也就是把阻塞的磁盘 I/O 丢给日志服务,不要阻塞对外的服务。(lua-resty-logger-socket 可以完成类似的工作)
local logger = require "resty.logger.socket"
if not logger.initted() then
local ok, err = logger.init{
host = 'xxx',
port = 1234,
flush_limit = 1234,
drop_limit = 5678,
}
local msg = "foo"
local bytes, err = logger.log(msg)luasocket
luasocket 也可以完成网络通信的功能,但它并没有非阻塞的优势。
cosocket 在不少阶段是无法使用的,我们一般可以用 ngx.timer 的方式来绕过。
同时,也可以在 init_by_lua* 和 init_worker_by_lua* 这种一次性的阶段中,使用 luasocket 来完成 cosocket 的功能。
字符串操作
性能优化理念
理念一:处理请求要短、平、快
- “短”,是指请求的生命周期要短,不要长时间占用资源而不释放;即使是长连接,也要设定一个时间或者请求次数的阈值,来定期地释放资源。
- “平”,则是指在一个 API 中只做一件事情。把复杂的业务逻辑拆散为多个 API,保持代码的简洁。
- “快”,是指不要阻塞主线程,不要有大量 CPU 运算。即使是不得不有这样的逻辑,也可以配合其他的服务去完成。
理念二:避免产生中间数据
$ resty -e 'local s= "hello"
s = s .. " world"
s = s .. "!"
print(s)
'这段代码,我们对s 这个变量做了多次拼接操作,才得到了hello world! 对结果。但很显然,只有 s 的最终状态,也就是 hello world! 这个状态是有用的。而 s 的初始值和中间的赋值,都属于中间数据,应该尽量少生成。
因为这些临时数据,会带来初始化和 GC 的性能损耗。如果这出现在循环等热代码中,就会带来非常明显的性能下降了。
字符串是不可变的!
在 Lua 中,字符串是不可变的。
在修改一个字符串的时候,其实并没有改变原来的字符串,而是产生了一个新的字符串对象,并改变了对字符串的引用。自然,如果原有字符串没有其他的任何引用,就会给 Lua 的 GC 给回收掉。
字符串不可变的优点是节省内存。同样内容的字符串在内存中就只有一份了,不同的变量都会指向同一个内存地址。
缺点是涉及到字符串的新增和 GC 时,每当新增一个字符串,LuaJIT 都得调用 lj_str_new,去查询这个字符串是否已经存在;没有的话,便需要再创建新的字符串。如果操作很频繁就会对性能有非常大的影响。
$ resty -e 'local begin = ngx.now()
local s = ""
-- for 循环,使用 .. 进行字符串拼接
for i = 1, 100000 do
s = s .. "a"
end
ngx.update_time()
print(ngx.now() - begin)
'这段示例代码的作用,是对s 变量做十万次字符串拼接,并把运行时间打印出来。虽然例子有些极端,但却能很好地体现出性能优化前后的差异。
当前在我的设备上运行了 0.27 秒
优化方式,使用 table 做一层封装
$ resty -e 'local begin = ngx.now()
local t = {}
-- for 循环,使用数组来保存字符串,每次都计算数组长度
for i = 1, 100000 do
t[#t + 1] = "a"
end
-- 使用数组的 concat 方法拼接字符串
local s = table.concat(t, "")
ngx.update_time()
print(ngx.now() - begin)
'用 table 依次保存了每一个字符串,下标由 #t + 1 来决定,也就是用 table 的当前长度加 1;最后,使用 table.concat 函数,把数组的每一个元素进行拼接,直接得到最终结果。跳过了所有的临时字符串,避免了 10 万次 lj_str_new 和 GC。
优化后运行耗时 0.002s,性能提升 135 倍。
$ resty -e 'local begin = ngx.now()
local t = {}
-- for 循环,使用数组来保存字符串,自己维护数组的长度
for i = 1, 100000 do
t[i] = "a"
end
local s = table.concat(t, "")
ngx.update_time()
print(ngx.now() - begin)
'这次,把 t[#t + 1] = "a" ,改为了 t[i] = "a",只修改了这一行代码。
或者显示的维护数组下标
$ resty -e 'local begin = ngx.now()
local t = {}
local index = 1
for i = 1, 100000 do
t[index] = "a"
index = index + 1
end
local s = table.concat(t, "")
ngx.update_time()
print(ngx.now() - begin)
'在我的设备上,两者耗时一模一样,说明如今的版本中,当前函数 # 获取数组长度的时间复杂度是 O(1),不要被旧文章给带偏了。
减少其他临时字符串
string.sub 函数的作用是截取字符串的指定部分
resty -e 'print(string.sub("abcd", 1, 1))'上面这段代码的作用,是获取字符串的第一个字符,并打印出来。那么截取出来的新字符串,就会涉及到 lj_str_new 和后续的 GC 操作。
resty -e 'print(string.char(string.byte("abcd")))'先用 string.byte 获取到第一个字符的数字编码,再用 string.char 把数字转为对应的字符。这个过程中并没有生成任何临时的字符串。因此,使用 string.byte 来完成字符串相关的扫描和分析,是效率最高的。
利用 SDK 对 table 类型的支持
$ resty -e 'local begin = ngx.now()
local t = {}
local index = 1
for i = 1, 100000 do
t[index] = "a"
index = index + 1
end
local response = table.concat(t, "")
ngx.say(response)
'这里利用 table 来做字符串拼接,效率已经很高了。
ngx.say、ngx.print 、ngx.log、cosocket:send,这些可能接受大量字符串的 API 中,它不仅接受 string 作为参数,也同时接受 table 作为参数:
resty -e 'local begin = ngx.now()
local t = {}
local index = 1
for i = 1, 100000 do
t[index] = "a"
index = index + 1
end
ngx.say(t)
'省略掉了 local response = table.concat(t, ""), 这个字符串拼接的步骤,直接把 table 传给了 ngx.say。这样,就把字符串拼接的任务,从 Lua 层面转移到了 C 层面,又避免了一次字符串的查找、生成和 GC。对于比较长的字符串而言,这又是一次不小的性能提升。
table
table 相关的优化,有一个自己的简单原则:
尽量复用,避免不必要的 table 创建。
预先生成数组
在 Lua 中,我们创建数组的方式很简单:
local t = {}的时候,加上初始化的数据:
local color = {first = "red", "blue", third = "green", "yellow"}不过,第二种写法对于性能的损失比较大,原因在于每次新增和删除数组元素的时候,都会涉及到数组的空间分配、resize 和 rehash。
LuaJIT 中的 table.new(narray, nhash) 函数,会预先分配好指定的数组和哈希的空间大小,而不是在插入元素时自增长,这也是它的两个参数 narray 和 nhash 的含义。
local new_tab = require "table.new"
local t = new_tab(100, 0)
for i = 1, 100 do
t[i] = i
end自己计算 table 下标(过时了)
由前文可知,luajit 获取长度的性能并不差,正常写代码就好,不要有太大的心理负担,下面的优化可以看作是远古程序员的优化小技巧
增加元素,最直接的方法,就是调用 table.insert 这个函数
local new_tab = require "table.new"
local t = new_tab(100, 0)
for i = 1, 100 do
table.insert(t, i)
end或者是先获取当前数组的长度,通过下标的方式来插入元素:
local new_tab = require "table.new"
local t = new_tab(100, 0)
for i = 1, 100 do
t[#t + 1] = i
end看下lua-resty-redis 这个官方的库是如何做的吧:
local function _gen_req(args)
local nargs = #args
local req = new_tab(nargs * 5 + 1, 0)
req[1] = "*" .. nargs .. "\r\n"
local nbits = 2
for i = 1, nargs do
local arg = args[i]
req[nbits] = "$"
req[nbits + 1] = #arg
req[nbits + 2] = "\r\n"
req[nbits + 3] = arg
req[nbits + 4] = "\r\n"
nbits = nbits + 5
end
return req
end这个函数预先生成了数组 req,它的大小由函数的入参来决定,这样就可以保证尽量不浪费空间。
然后,它使用 nbits 这个变量,来自己维护 req 的下标,自然就抛弃了 Lua 内置的 table.insert 函数和获取长度的操作符 #。你可以看到,在 for 循环中,nbits + 1 等一些运算,就是直接用下标的方式插入元素;并在最后用 nbits = nbits + 5 ,让下标保持一个正确的值。
这种的好处很明显,它省略了获取数组大小这个 O(n) 的操作,而是直接用下标访问,时间复杂度也变成了 O(1) 。当然,缺点也一样明显,那就是降低了代码的可读性,并且出错概率大大提高,可以说,这是一把双刃剑。
循环使用单个 table
table.clear 函数,它会把数组中的所有数据清空,但数组的大小不会变。
也就是说,用 table.new(narray, nhash) 生了一个长度为 100 的数组,clear 后,长度还是 100。
local ok, clear_tab = pcall(require, "table.clear")
if not ok then
clear_tab = function (tab)
for k, _ in pairs(tab) do
tab[k] = nil
end
end
endclear 函数实际上就是把每一个元素都置为了 nil。
下面这段 伪代码 取自开源的微服务 API 网关 APISIX,这是它在加载插件时候的逻辑:
local local_plugins = {}
function load()
core.table.clear(local_plugins)
local local_conf = core.config.local_conf()
local plugin_names = local_conf.plugins
local processed = {}
for _, name in ipairs(plugin_names) do
if processed[name] == nil then
processed[name] = true
insert_tab(local_plugins, name)
end
end
return local_plugins
endlocal_plugins 这个数组,是 plugin 这个模块的 top level 变量。在 load 这个加载插件函数的开始位置, table 就会被清空,然后根据当前的情况生成新的插件列表。
table 池
lua-tablepool 缓存池的方式来保存多个 table,以便随用随取
local tablepool = require "tablepool"
local tablepool_fetch = tablepool.fetch
local tablepool_release = tablepool.release
local pool_name = "some_tag"
local function do_sth()
local t = tablepool_fetch(pool_name, 10, 0)
-- -- using t for some purposes
tablepool_release(pool_name, t)
endfetch 方法,它的参数和 table.new 基本一样,只是多了一个 pool_name。如果池子中没有空闲的数组,fetch 方法就会调用 table.new 来新建一个数组。
tablepool.fetch(pool_name, narr, nrec)release 这个把 table 放回池子的函数。在它的参数中,最后的 no_clear ,用来配置是否要调用 table.clear 把数组清空。
tablepool.release(pool_name, tb, [no_clear])注意不要因此滥用 tablepool。tablepool 在实际项目中的使用并不多,比如 Kong 中就没有用到,APISIX 也只有少数几个调用。大多数情况下,不用 tablepool 的这层封装,也是足够我们使用的。
缓存
一般来说,缓存有两个原则。
- 一是越靠近用户的请求越好。比如,能用本地缓存的就不要发送 HTTP 请求,能用 CDN 缓存的就不要打到源站,能用 OpenResty 缓存的就不要打到数据库。
- 二是尽量使用本进程和本机的缓存解决。因为跨了进程和机器甚至机房,缓存的网络开销就会非常大,这一点在高并发的时候会非常明显。
OpenResty 中有两个缓存的组件:shared dict 缓存和 lru 缓存。前者只能缓存字符串对象,缓存的数据有且只有一份,每一个 worker 都可以进行访问,所以常用于 worker 之间的数据通信。后者则可以缓存所有的 Lua 对象,但只能在单个 worker 进程内访问,有多少个 worker,就会有多少份缓存数据。


共享字典缓存
$ resty --shdict='dogs 1m' -e 'local dict = ngx.shared.dogs
dict:set("Tom", 56)
print(dict:get("Tom"))'需要事先在 Nginx 的配置文件中,声明一个内存区 dogs,然后在 Lua 代码中才可以使用。如果你在使用的过程中,发现给 dogs 分配的空间不够用,那么是需要先修改 Nginx 配置文件,然后重新加载 Nginx 才能生效的。因为我们并不能在运行时进行扩容和缩容。
缓存数据的序列化
由于共享字典中只能缓存字符串对象,所以,如果想要缓存数组,就少不了要在 set 的时候要做一次序列化,在 get 的时候做一次反序列化:
resty --shdict='dogs 1m' -e 'local dict = ngx.shared.dogs
dict:set("Tom", require("cjson").encode({a=111}))
print(require("cjson").decode(dict:get("Tom")).a)'不过,这类序列化和反序列化操作是非常消耗 CPU 资源的。如果每个请求都有那么几次这种操作,那么,在火焰图上你就能很明显地看到它们的消耗。(没有更好的解决方案)
此外,缓存中的 key 也应该尽量选择短和有意义的。
stale 数据
共享字典中还有一个 get_stale 的读取数据的方法,相比 get 方法,多了一个过期数据的返回值:
resty --shdict='dogs 1m' -e 'local dict = ngx.shared.dogs
dict:set("Tom", 56, 0.01)
ngx.sleep(0.02)
local val, flags, stale = dict:get_stale("Tom")
print(val)'在上面的这个示例中,数据只在共享字典中缓存了 0.01 秒,在 set 后的 0.02 秒后,数据就已经超时了。这时候,通过 get 接口就不会获取到数据了,但通过 get_stale 还可能获取到过期的数据。这里之所以用“可能”两个字,是因为过期数据所占用的空间,是有一定几率被回收,再给其他数据使用的,这也就是 LRU 算法。
获取已经过期的数据有什么用呢?
缓存数据过期了,也并不意味着源数据就一定有更新。
举个例子,数据源存储在 MySQL 中,我们从 MySQL 中获取到数据后,在 shared dict 中设置了 5 秒超时,那么,当这个数据过期后,我们就会有两个选择:
- 当这个数据不存在时,重新去 MySQL 中再查询一次,把结果放到缓存中;
- 判断 MySQL 的数据是否发生了变化,如果没有变化,就把缓存中过期的数据读取出来,修改它的过期时间,让它继续生效。
很明显,后者是更优化的方案,这样可以尽可能少地去和 MySQL 交互,让终端的请求都从最快的缓存中获取数据。
lru 缓存
lru 缓存的接口:new、set、get、delete 和 flush_all
resty -e 'local lrucache = require "resty.lrucache"
local cache, err = lrucache.new(200)
cache:set("dog", 32, 0.01)
ngx.sleep(0.02)
local data, stale_data = cache:get("dog")
print(stale_data)'可以看到,在 lru 缓存中, get 接口的第二个返回值直接就是 stale_data,而不是像 shared dict 那样分为了 get 和 get_stale 两个不同的 API。这样的接口封装,对于使用过期数据来说显然更加友好。
在实际的项目中,一般推荐使用版本号来区分不同的数据,这样,在数据发生变化后,它的版本号也就跟着变了。
比如,在 etcd 中的 modifiedIndex ,就可以拿来当作版本号,来标记数据是否发生了变化。有了版本号的概念后,我们就可以对 lru 缓存做一个简单的二次封装,比如来看下面的伪码,摘自 https://github.com/apache/apisix/blob/master/apisix/core/lrucache.lua :
local function (key, version, create_obj_fun, ...)
local obj, stale_obj = lru_obj:get(key)
-- 如果数据没有过期,并且版本没有变化,就直接返回缓存数据
if obj and obj._cache_ver == version then
return obj
end
-- 如果数据已经过期,但还能获取到,并且版本没有变化,就直接返回缓存中的过期数据
if stale_obj and stale_obj._cache_ver == version then
lru_obj:set(key, obj, item_ttl)
return stale_obj
end
-- 如果找不到过期数据,或者版本号有变化,就从数据源获取数据
local obj, err = create_obj_fun(...)
obj._cache_ver = version
lru_obj:set(key, obj, item_ttl)
return obj, err
end从这段代码中你可以看到,通过引入版本号的概念,在版本号没有变化的情况下,充分利用了过期数据来减少对数据源的压力,达到了性能的最优。
缓存风暴
比如缓存超时时间为 60 秒,60s 时同时失效,大量请求直接打到数据库。
local value = get_from_cache(key)
if not value then
value = query_db(sql)
set_to_cache(value, timeout = 60)
end
return value如何避免
主动更新缓存
蠢方法,不好用
使用 ngx.timer.every 来创建一个定时任务,每分钟运行一次,去 MySQL 数据库中获取最新的数据,并放入共享字典中:
local function query_db(premature, sql)
local value = query_db(sql)
set_to_cache(value, timeout = 60)
end
local ok, err = ngx.timer.every(60, query_db, sql)在终端请求的代码逻辑中,去掉查询 MySQL 的部分,只保留获取共享字典缓存的代码:
local value = get_from_cache(key)
return value这样的每一个缓存都要对应一个周期性的任务(OpenResty 中 timer 是有上限的,不能太多);而且缓存过期时间和计划任务的周期时间还要对应好,如果这中间出现了什么纰漏,终端就可能一直获取到的都是空数据。
lua-resty-lock
lua-resty-lock 是 OpenResty 自带的 resty 库,它底层是基于共享字典,提供非阻塞的 lock API。
resty --shdict='locks 1m' -e 'local resty_lock = require "resty.lock"
local lock, err = resty_lock:new("locks")
local elapsed, err = lock:lock("my_key")
-- query db and update cache
local ok, err = lock:unlock()
ngx.say("unlock: ", ok)'因为 lua-resty-lock 是基于共享字典来实现的,所以需要事先声明 shdict 的名字和大小;
然后,再使用 new 方法来新建 lock 对象。
可以看到,这段代码中,我们只传了第一个参数 shdict 的名字。其实, new 方法还有第二个参数,可以用来指定锁的过期时间、等待锁的超时时间等多个参数。不过这里,我们使用的是默认值,它们就是用来避免死锁等各种异常问题的。
接着,我们就可以调用 lock 方法尝试获取锁。如果成功获取到锁的话,那就可以保证只有一个请求去数据源更新数据;而如果因为锁已经被抢占、超时等导致加锁失败,那就需要从陈旧的缓存中获取数据( get_stale API):
local elapsed, err = lock:lock("my_key")
# elapsed 为 nil 表示加锁失败,err的返回值是 timeout、 locked 中的一个
if not elapsed and err then
dict:get_stale("my_key")
end如果 lock 成功,那么就可以安全地去查询数据库,并把结果更新到缓存中。最后,我们再调用 unlock 接口,把锁释放掉就可以了。
结合 lua-resty-lock 和 get_stale,我们就完美地解决了缓存风暴的问题。在 lua-resty-lock 的文档中,给出了非常完整的处理代码。
lock 这个接口是如何加锁的,下面便是它的源码:
local ok, err = dict:add(key, true, exptime)
if ok then
cdata.key_id = ref_obj(key)
self.key = key
return 0
endshared dict 的所有 API 都是原子操作,不用担心出现竞争,这里 lock 接口的实现,便使用了 dict:add 接口来尝试设置 key。如果 key 在共享内存中不存在,add 接口就会返回成功,表示加锁成功;其他并发的请求走到 dict:add 这一行的代码逻辑时,就会返回失败,然后根据返回的 err 信息,选择是直接返回,还是多次重试。
Nginx 配置指令
另外,即使你没有使用 OpenResty 的 lua-resty 库,你也可以用 Nginx 的配置指令,来实现加锁和获取过期数据——即proxy_cache_lock 和 proxy_cache_use_stale。不过,这里我并不推荐使用 Nginx 指令这种方式,它显然不够灵活,性能也比不上 Lua 代码。
lua-resty-_ 封装
lua-resty-memcached-shdict
知道有这么个东西就好,不会用的
lua-resty-memcached-shdict 是 OpenResty 官方的一个项目,它使用 shared dict 为 memcached 做了一层封装,处理了缓存风暴和过期数据等细节。如果你的缓存数据正好存储在后端的 memcached 中,那么你可以尝试使用这个库。
默认并没有打进 OpenResty 的包中。如果你想在本地测试,需要先把它的源码下载到本地 OpenResty 的查找路径下。
它使用 lua-resty-lock 来做到互斥,在缓存失效的情况下,只有一个请求去 memcached 中获取数据,避免缓存风暴。如果没有获取到最新数据,则使用 stale 数据返回给终端。
首先,它没有测试案例覆盖,这就意味着代码质量无法得到持续的保证;其次,它暴露的接口参数过多,有 11 个必填参数和 7 个选填参数。
lua-resty-mlcache
在 OpenResty 中被普遍使用的缓存封装:lua-resty-mlcache。它使用 shared dict 和 lua-resty-lrucache ,实现了多层缓存机制。我们下面就通过两段代码示例,来看看这个库如何使用:
local mlcache = require "resty.mlcache"
local cache, err = mlcache.new("cache_name", "cache_dict", {
lru_size = 500, -- size of the L1 (Lua VM) cache
ttl = 3600, -- 1h ttl for hits
neg_ttl = 30, -- 30s ttl for misses
})
if not cache then
error("failed to create mlcache: " .. err)
end这段代码的开头引入了 mlcache 库,并设置了初始化的参数。我们一般会把这段代码放到 init 阶段,只需要做一次就可以了。
除了缓冲名和字典名这两个必填的参数外,第三个参数是一个字典,里面 12 个选项都是选填的,不填的话就使用默认值。这种方式显然就比 lua-resty-memcached-shdict 要优雅很多。
local function fetch_user(id)
return db:query_user(id)
end
local id = 123
local user , err = cache:get(id , nil , fetch_user , id)
if err then
ngx.log(ngx.ERR , "failed to fetch user: ", err)
return
end
if user then
print(user.id) -- 123
end可以看到,这里已经把多层缓存都给隐藏了,你只需要使用 mlcache 的对象去获取缓存,并同时设置好缓存失效后的回调函数就可以了。这背后复杂的逻辑,就可以被完全地隐藏了。
┌─────────────────────────────────────────────────┐
│ Nginx │
│ ┌───────────┐ ┌───────────┐ ┌───────────┐ │
│ │worker │ │worker │ │worker │ │
│ L1 │ │ │ │ │ │ │
│ │ Lua cache │ │ Lua cache │ │ Lua cache │ │
│ └───────────┘ └───────────┘ └───────────┘ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌───────────────────────────────────────┐ │
│ │ │ │
│ L2 │ lua_shared_dict │ │
│ │ │ │
│ └───────────────────────────────────────┘ │
│ │ mutex │
│ ▼ │
│ ┌──────────────────┐ │
│ │ callback │ │
│ └────────┬─────────┘ │
└───────────────────────────┼─────────────────────┘
│
L3 │ I/O fetch
▼
Database, API, DNS, Disk, any I/O...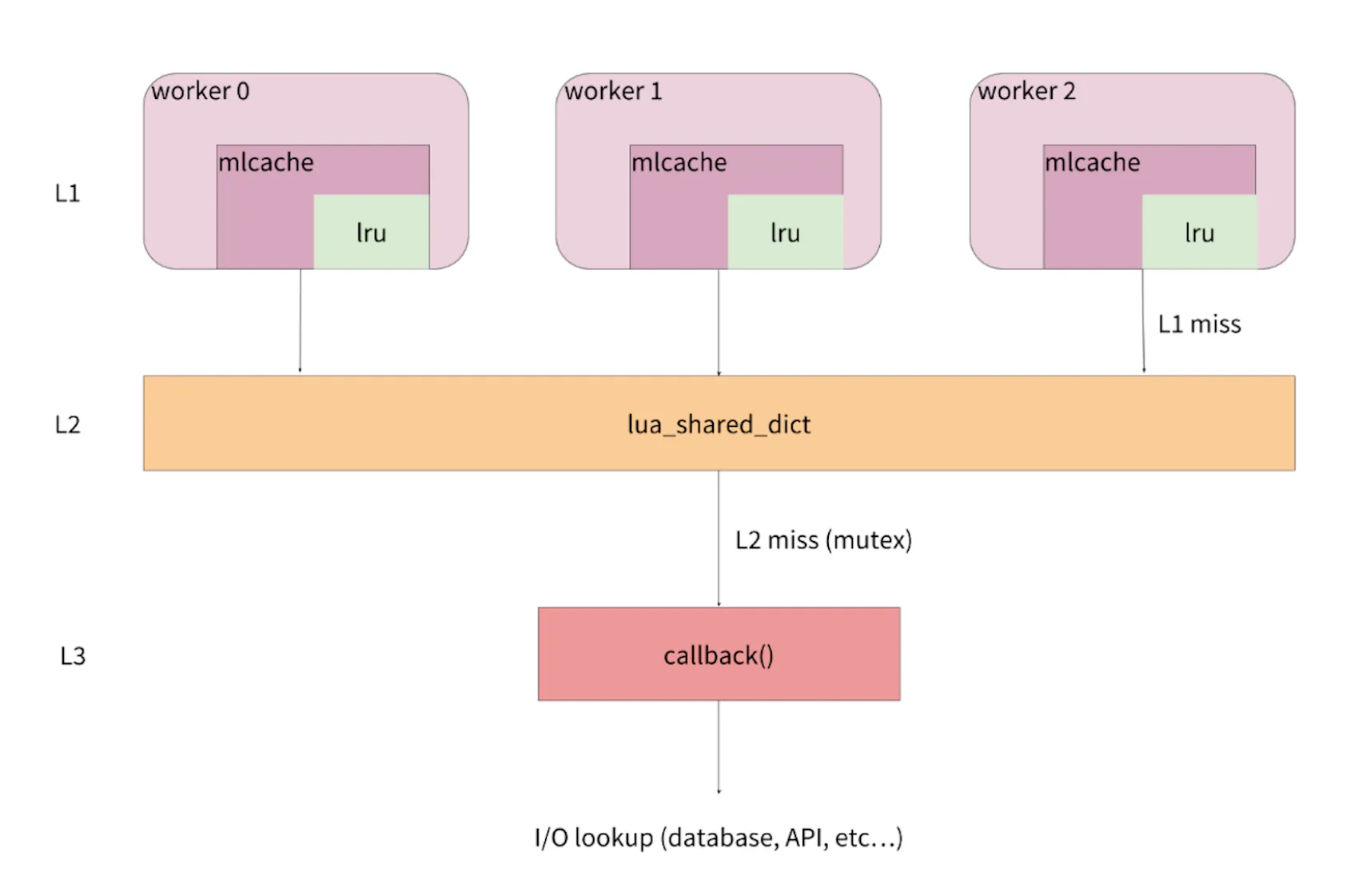
mlcache 把数据分为了三层,即 L1、L2 和 L3。
-
L1 缓存就是 lua-resty-lrucache。每一个 worker 中都有自己独立的一份,有 N 个 worker,就会有 N 份数据,自然也就存在数据冗余。由于在单 worker 内操作 lrucache 不会触发锁,所以它的性能更高,适合作为第一级缓存。
-
L2 缓存是 shared dict。所有的 worker 共用一份缓存数据,在 L1 缓存没有命中的情况下,就会来查询 L2 缓存。ngx.shared.DICT 提供的 API,使用了自旋锁来保证操作的原子性,所以这里我们并不用担心竞争的问题;
-
L3 则是在 L2 缓存也没有命中的情况下,需要执行回调函数去外部数据库等数据源查询后,再缓存到 L2 中。在这里,为了避免缓存风暴,它会使用 lua-resty-lock ,来保证只有一个 worker 去数据源获取数据。
整体而言,从请求的角度来看,
- 首先会去查询 worker 内的 L1 缓存,如果 L1 命中就直接返回。
- 如果 L1 没有命中或者缓存失效,就会去查询 worker 间的 L2 缓存。如果 L2 命中就返回,并把结果缓存到 L1 中。
- 如果 L2 也没有命中或者缓存失效,就会调用回调函数,从数据源中查到数据,并写入到 L2 缓存中,这也就是 L3 数据层的功能。
从这个过程你也可以看出,缓存的更新是由终端请求来被动触发的。即使某个请求获取缓存失败了,后续的请求依然可以触发更新的逻辑,以便最大程度地保证缓存的安全性。
对于序列化和反序列化,mlcache 在 new 和 get 接口中,提供了可选的函数 l1_serializer,专门用于处理 L2 提升到 L1 时对数据的处理。
local mlcache = require "resty.mlcache"
local cache, err = mlcache.new("my_mlcache", "cache_shm", {
l1_serializer = function(i)
return i + 2
end,
})
local function callback()
return 123456
end
local data = assert(cache:get("number", nil, callback))
assert(data == 123458)在这个案例中,回调函数返回数字 123456;而在 new 中,我们设置的 l1_serializer 函数会在设置 L1 缓存前,把传入的数字加 2,也就是变成 123458。通过这样的序列化函数,数据在 L1 和 L2 之间转换的时候,就可以更加灵活了。
突发流量:漏桶和令牌桶
漏桶算法
它的目的是让请求的速率保持恒定,把突发的流量变得平滑。不过,它是怎么做到的呢?
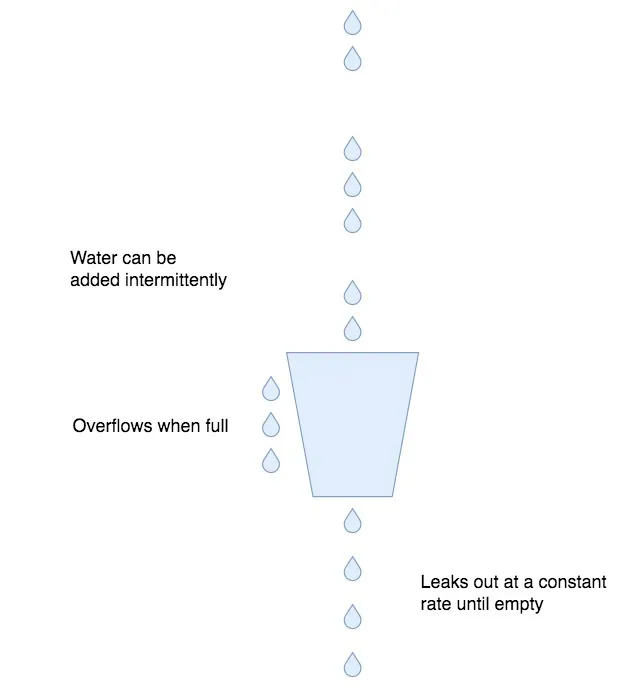
我们可以把客户端的流量想象成是从水管中流出来的水,水的流速不确定,忽快忽慢;而外层的流量处理模块,就是接水的桶子,并且这个水桶的底部有一个漏水用的洞眼。这其实也就是漏桶算法名字的由来,很明显,这种算法有下面几个好处。
第一,不管流入水桶的是涓涓细流还是滔天洪水,都可以保证,水桶中流出来的水速是恒定的。这种稳定的流量对于上游服务是很友好的,这也是流量整形的意义。
第二,水桶本身有一定容积,可以积累一定的水来等待流出水桶。这对于终端的请求来说,相当于是如果不能被立即处理,可以排队等待。
第三,超过水桶容积的水,不会被水桶接纳,而是会直接流走。这里对应的是,终端的请求如果太多,超过了排队的长度,就直接返回给客户端失败信息。这时候的服务端已经处理不过来了,自然,请求连排队的必要也就没有了。
OpenResty 中自带的 resty.limit.req 库 为例来看,它就是按照漏桶算法实现的限速模块,下面是它关键的几行代码:
local elapsed = now - tonumber(rec.last)
excess = max(tonumber(rec.excess) - rate * abs(elapsed) / 1000 + 1000,0)
if excess > self.burst then
return nil, "rejected"
end
-- return the delay in seconds, as well as excess
return excess / rate, excess / 1000其中, elapsed 是当前请求和上一次请求之间的毫秒数,rate 则是我们设定的每秒的速率。因为rate的最小单位是 0.001 s/r,所以在上述实现的代码中,都需要乘以 1000 以便计算。
excess 表示还在排队的请求数量,它为 0 表示水桶是空的,没有请求在排队,而burst 是指整个水桶的容积。如果 excess 已经大于 burst,也就意味着水桶已经满了,这时候再进来的流量就会被直接丢弃;如果 excess 大于 0 、小于 burst,就进入了排队来等待处理,这里最后返回的 excess / rate ,也就是要等待的时间。
这样,在后端服务处理能力不变的情况下,我们就可以通过调节 burst 的大小,来控制突发流量的排队时长了。
令牌桶算法
令牌桶算法和漏桶算法的目的都是一样的,用来保证后端服务不被突发流量打垮,不过这两者的实现方式并不相同。
在漏桶算法中,我们一般会使用终端 IP 作为 key ,来做限流限速的依据。这样,对于每一个终端用户而言,漏桶算法的出口速率就是固定的。不过,这就会存在一个问题:
如果 A 用户的请求频率很高,而其他用户的请求频率很低,即使此时的整体服务压力并不大,但漏桶算法就会把 A 的部分请求变慢或者拒绝掉,虽然这时候服务其实是可以处理的。
漏桶算法关注的是流量的平滑,而令牌桶则可以允许突发流量进入后端服务。令牌桶的原理,是以一个固定的速度向水桶内放入令牌,只要桶没有满就一直往里面放。这样,终端过来的请求都需要先到令牌桶中获取到令牌,才可以被后端处理;如果桶里面没有令牌,那么请求就会被拒绝。
这里以lua-resty-limit-rate 的代码为例
local limit_rate = require "resty.limit.rate"
-- global 20r/s 6000r/5m
local lim_global = limit_rate.new("my_limit_rate_store", 100, 6000, 2)
-- single 2r/s 600r/5m
local lim_single = limit_rate.new("my_limit_rate_store", 500, 600, 1)
local t0, err = lim_global:take_available("__global__", 1)
local t1, err = lim_single:take_available(ngx.var.arg_userid, 1)
if t0 == 1 then
return -- global bucket is not hungry
else
if t1 == 1 then
return -- single bucket is not hungry
else
return ngx.exit(503)
end
end在这段代码中,我们设置了两个令牌桶:一个是全局的令牌桶,一个是以 b ngx.var.arg_userid 为 key,按照用户来划分的令牌桶。这里用两个令牌桶做了一个组合,主要有这么一个好处:
- 在全局令牌桶还有令牌的情况下,不用去判断用户的令牌桶,如果后端服务能够正常运行,就尽可能多地去服务用户的突发请求;
- 在全局令牌桶没有令牌的情况下,不能无差别地拒绝请求,这时候就需要判断下单个用户的令牌桶,把突发请求比较多的用户请求给拒绝掉。这样一来,就可以保证其他用户的请求不会受到影响。
显然,令牌桶和漏桶相比,更具有弹性,允许出现突发流量传递到后端服务的情况。当然,它们都各有利弊,可以根据自己的情况来选择使用。
Nginx 的限速模块
在 Nginx 中,limit_req 模块是最常用的限速模块,下面是一个简单的配置:
limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;
server {
location /search/ {
limit_req zone=one burst=5;
}
}这段代码是把终端的 IP 地址作为 key,申请了一块名为 one 的 10M 的内存空间地址,并把速率限制为每秒 1 个请求。
在 server 的 location 中,还引用了 one 这个限速规则,并把 brust 设置为 5。这就表示在超过速率 1r/s 的情况下,同时允许有 5 个请求排队等待被处理,给出了一定的缓存区。要注意,如果没有设置 brust ,超过速率的请求是会被直接拒绝的。
Nginx 的这个模块是基于漏桶来实现的,所以和我们上面介绍过的 OpenResty 中的 resty.limit.req ,本质都是一样的。
Nginx 中设置限流限速的最大问题是,无法动态地修改。毕竟,修改完配置文件后,还需要重启才能生效。
lua-resty-limit-traffic
它里面包含了 limit-req(限制请求速率)、 limit-count(限制请求数) 和 limit-conn (限制并发连接数)这三种不同的限制方式;并且提供了limit.traffic ,可以把这三种方式进行聚合使用。
限制请求速率
让我们先来看下 limit-req,它使用的是漏桶算法来限制请求的速率。
resty --shdict='my_limit_req_store 100m' -e 'local limit_req = require "resty.limit.req"
local lim, err = limit_req.new("my_limit_req_store", 200, 100)
local delay, err = lim:incoming("key", true)
if not delay then
if err == "rejected" then
return ngx.exit(503)
end
return ngx.exit(500)
end
if delay >= 0.001 then
ngx.sleep(delay)
end'我们知道,lua-resty-limit-traffic 是使用共享字典来对 key 进行保存和计数的,所以在使用 limit-req 前,我们需要先声明 my_limit_req_store 这个 100m 的空间。这一点对于 limit-conn 和 limit-count 也是类似的,它们都需要自己单独的共享字典空间,以便区分开。
limit_req.new("my_limit_req_store", 200, 100)上面这行代码,便是其中最关键的一行代码。它的含义,是使用名为 my_limit_req_store 的共享字典来存放统计数据,并把每秒的速率设置为 200。这样,如果超过 200 但小于 300(这个值是 200 + 100 计算得到的) 的话,就需要排队等候;如果超过 300 的话,就会直接拒绝。
lim:incoming("key", true) 就是来做这件事情的。incoming这个函数有两个参数
-
第一个参数,是用户指定的限速的 key。在上面的示例中它是一个字符串常量,这就意味着要对所有终端都统一限速。如果要实现根据不同省份和渠道来限速,其实也很简单,把这两个信息都作为 key 即可,下面是实现这一需求的伪代码:
local province = get_province(ngx.var.binary_remote_addr) local channel = ngx.req.get_headers()["channel"] local key = province .. channel lim:incoming(key, true)当然,也可以自定义 key 的含义以及调用
incoming的条件 -
第二个参数,它是一个布尔值,默认是 false,意味着这个请求不会被记录到共享字典中做统计,这只是一次
演习。如果设置为 true,就会产生实际的效果了。因此,在大多数情况下,你都需要显式地把它设置为 true。为什么会有这个参数的存在呢?我们不妨考虑一下这样的一个场景,设置了两个不同的
limit-req实例,针对不同的 key,一个 key 是主机名,另外一个 key 是客户端的 IP 地址。那么,当一个终端请求被处理的时候,会按照先后顺序调用这两个实例的incoming方法,就像下面这段伪码表示的一样:local limiter_one, err = limit_req.new("my_limit_req_store", 200, 100) local limiter_two, err = limit_req.new("my_limit_req_store", 20, 10) limiter_one :incoming(ngx.var.host, true) limiter_two:incoming(ngx.var.binary_remote_addr, true)如果用户的请求通过了
limiter_one的阈值检测,但被limiter_two的检测拒绝,那么limiter_one:incoming这次函数调用就应该被认为是一次演习,不应该真的去计数。这样一来,上述的代码逻辑就不够严谨了。我们需要事先对所有的 limiter 做一次演习,如果有 limiter 的阈值被触发,可以 rejected 终端请求,就可以直接返回:
for i = 1, n do local lim = limiters[i] local delay, err = lim:incoming(keys[i], i == n) if not delay then return nil, err end end这其实就是
incoming函数第二个参数的意义所在。刚刚这段代码就是limit.traffic模块最核心的一段代码,专门用作多个限流器的组合所用。
限制请求数
再来看下 limit.count 这个限制请求数的库,它可以限制固定时间窗口内有多少次用户请求。
local limit_count = require "resty.limit.count"
local lim, err = limit_count.new("my_limit_count_store", 5000, 3600)
local key = ngx.req.get_headers()["Authorization"]
local delay, remaining = lim:incoming(key, true)可以看到,limit.count 和 limit.req 的使用方法是类似的,我们先在 Nginx.conf 中定义一个字典:
lua_shared_dict my_limit_count_store 100m;然后 new 一个 limiter 对象,最后用 incoming 函数来判断和处理。
不过,不同的是,limit-count 中的incoming 函数的第二个返回值,代表着还剩余的调用次数,我们可以据此在响应头中增加字段,给终端更好的提示:
ngx.header["X-RateLimit-Limit"] = "5000"
ngx.header["X-RateLimit-Remaining"] = remaining限制并发连接数
前面所讲的限制请求速率和限制请求数,都是可以直接在 access 这一个阶段内完成的。而限制并发连接数则不同,它不仅需要在 access 阶段判断是否超过阈值,而且需要在 log 阶段调用 leaving 接口:
log_by_lua_block {
local latency = tonumber(ngx.var.request_time) - ctx.limit_conn_delay
local key = ctx.limit_conn_key
local conn, err = lim:leaving(key, latency)
}不过,这个接口的核心代码其实也很简单,也就是下面这一行代码,实际上就是把连接数减一的操作。如果你没有在 log 阶段做这个清理的动作,那么连接数就会一直上涨,很快就会达到并发的阈值。
local conn, err = dict:incr(key, -1)限速器的组合
local lim1, err = limit_req.new("my_req_store", 300, 200)
local lim2, err = limit_req.new("my_req_store", 200, 100)
local lim3, err = limit_conn.new("my_conn_store", 1000, 1000, 0.5)
local limiters = {lim1, lim2, lim3}
local host = ngx.var.host
local client = ngx.var.binary_remote_addr
local keys = {host, client, client}
local delay, err = limit_traffic.combine(limiters, keys, states)combine 函数的核心代码,在我们上面分析 limit.rate 的时候已经提到了一部分,它主要是借助了演习功能和 uncommit 函数来实现。这样组合以后,你就可以为多个限流器设置不同的阈值和 key,实现更复杂的业务需求了。
OpenResty 编码指南
自动化检测代码风格的工具:luacheck 和 lj-releng
缩进
在 OpenResty 中,我们使用 4 个空格作为缩进的标记,虽然 Lua 并没有这样的语法要求。下面是错误和正确的两段代码示例:
--No
if a then
ngx.say("hello")
end
--yes
if a then
ngx.say("hello")
end为了方便,你可以在使用的编辑器中,把 tab 改为 4 个空格,来简化操作。
空格
在操作符的两边,都需要用一个空格来做分隔。下面是错误和正确的两段代码示例:
--No
local i=1
local s = "apisix"
--Yes
local i = 1
local s = "apisix"空行
不少开发者会把其他语言的开发习惯带到 OpenResty 中来,比如在行尾增加一个分号:
--No
if a then
ngx.say("hello");
end;但事实上,增加分号会让 Lua 代码显得非常丑陋,也是没有必要的。同时,你也不要为了节省代码的行数,追求所谓的“简洁”,而把多行代码变为一行。这样做会让你在定位错误的时候,不知道到底是哪一段代码出了问题:
--No
if a then ngx.say("hello") end
--yes
if a then
ngx.say("hello")
end另外,函数之间需要用两个空行来做分隔:
--No
local function foo()
end
local function bar()
end
--Yes
local function foo()
end
local function bar()
end如果有多个 if elseif 的分支,它们之间也需要一个空行来做分隔:
--No
if a == 1 then
foo()
elseif a== 2 then
bar()
elseif a == 3 then
run()
else
error()
end
--Yes
if a == 1 then
foo()
elseif a== 2 then
bar()
elseif a == 3 then
run()
else
error()
end每行最大长度
每行不能超过 80 个字符,如果超过的话,需要你换行并对齐。并且,在换行对齐的时候,我们要体现出上下两行的对应关系。就下面的示例而言,第二行函数的参数,要在第一行左括号的右边。
--No
return limit_conn_new("plugin-limit-conn", conf.conn, conf.burst, conf.default_conn_delay)
--Yes
return limit_conn_new("plugin-limit-conn", conf.conn, conf.burst,
conf.default_conn_delay)如果是字符串拼接问题的对齐,则需要把 .. 放到下一行中:
--No
return limit_conn_new("plugin-limit-conn" .. "plugin-limit-conn" ..
"plugin-limit-conn")
--Yes
return limit_conn_new("plugin-limit-conn" .. "plugin-limit-conn"
.. "plugin-limit-conn")变量
这一点我前面也多次强调过,我们应该永远使用局部变量,不要使用全局变量:
--No
i = 1
s = "apisix"
--Yes
local i = 1
local s = "apisix"至于变量的命名,应该使用 snake_case 风格:
--No
local IndexArr = 1
local str_Name = "apisix"
--Yes
local index_arr = 1
local str_name = "apisix"而对于常量,则是要使用全部大写的形式:
--No
local max_int = 65535
local server_name = "apisix"
--Yes
local MAX_INT = 65535
local SERVER_NAME = "apisix"数组
在 OpenResty 中,我们使用table.new 来预先分配数组:
--No
local t = {}
for i = 1, 100 do
t[i] = i
end
--Yes
local new_tab = require "table.new"
local t = new_tab(100, 0)
for i = 1, 100 do
t[i] = i
end另外注意,一定不要在数组中使用 nil:
--No
local t = {1, 2, nil, 3}如果一定要使用空值,请用 ngx.null 来表示:
--Yes
local t = {1, 2, ngx.null, 3}字符串
千万不要在热代码路径上拼接字符串:
--No
local s = ""
for i = 1, 100000 do
s = s .. "a"
end
--Yes
local t = {}
for i = 1, 100000 do
t[i] = "a"
end
local s = table.concat(t, "")函数
函数的命名也同样遵循 snake_case:
--No
local function testNginx()
end
--Yes
local function test_nginx()
end并且,函数应该尽可能早地返回:
--No
local function check(age, name)
local ret = true
if age < 20 then
ret = false
end
if name == "a" then
ret = false
end
-- do something else
return ret
--Yes
local function check(age, name)
if age < 20 then
return false
end
if name == "a" then
return false
end
-- do something else
return true模块
所有 require 的库都要 local 化:
--No
local function foo()
local ok, err = ngx.timer.at(delay, handler)
end
--Yes
local timer_at = ngx.timer.at
local function foo()
local ok, err = timer_at(delay, handler)
end为了风格的统一,require 和 ngx 也需要 local 化:
--No
local core = require("apisix.core")
local timer_at = ngx.timer.at
local function foo()
local ok, err = timer_at(delay, handler)
end
--Yes
local ngx = ngx
local require = require
local core = require("apisix.core")
local timer_at = ngx.timer.at
local function foo()
local ok, err = timer_at(delay, handler)
end错误处理
对于有错误信息返回的函数,我们必须对错误信息进行判断和处理:
--No
local sock = ngx.socket.tcp()
local ok = sock:connect("www.google.com", 80)
ngx.say("successfully connected to google!")
--Yes
local sock = ngx.socket.tcp()
local ok, err = sock:connect("www.google.com", 80)
if not ok then
ngx.say("failed to connect to google: ", err)
return
end
ngx.say("successfully connected to google!")而如果是自己编写的函数,错误信息要作为第二个参数,用字符串的格式返回:
--No
local function foo()
local ok, err = func()
if not ok then
return false
end
return true
end
--No
local function foo()
local ok, err = func()
if not ok then
return false, {msg = err}
end
return true
end
--Yes
local function foo()
local ok, err = func()
if not ok then
return false, "failed to call func(): " .. err
end
return true
end