- OpenResty 学习笔记(目录)
- OpenResty 学习笔记(2) - 前置知识
- OpenResty 学习笔记(3) - LuaJIT
- OpenResty 学习笔记(4) - OpenResty 原理和 API
- OpenResty 学习笔记(5) - shared dict、cosocket、特权进程
- OpenResty 学习笔记(6) - 测试工具
- OpenResty 学习笔记(7) - 性能优化和编码指南
- OpenResty 学习笔记(8) - 动态调试
目录
shared dict
共享内存字典 shared dict, 支持数据的存放和读取,以及原子计数和队列操作。
基于 shared dict,可以实现多个 worker 之间的缓存和通信,以及限流限速、流量统计等功能。
可以当作不可持久化数据的 Redis 来使用。
数据共享的几种方式
-
Nginx 中的变量。它可以在 Nginx C 模块之间共享数据。
location /foo { set $my_var ''; # this line is required to create $my_var at config time content_by_lua_block { ngx.var.my_var = 123; ... } }缺点:
- 速度较慢。因为涉及到 hash 查找和内存分配。
- 只能用来存储字符串,不能支持复杂的 Lua 类型。
-
ngx.ctx,可以在同一个请求的不同阶段之间共享数据。它其实就是一个普通的 Lua 的 table,所以速度很快,还可以存储各种 Lua 的对象。它的生命周期是请求级别的,当一个请求结束的时候,ngx.ctx也会跟着被销毁掉。比如,用
ngx.ctx来缓存Nginx 变量这种昂贵的调用,并在不同阶段都可以使用到location /test { rewrite_by_lua_block { ngx.ctx.host = ngx.var.host } access_by_lua_block { if (ngx.ctx.host == 'openresty.org') then ngx.ctx.host = 'test.com' end } content_by_lua_block { ngx.say(ngx.ctx.host) } }缺点:生命周期是请求级别的,不能在模块级别进行缓存。
比如这样使用是错误的:
local ngx_ctx = ngx.ctx local function bar() ngx_ctx.host = 'test.com' end应该这样:
local ngx = ngx local function bar() ngx.ctx.host = 'test.com' end -
模块级别的变量,在同一个 worker 内的所有请求之间共享数据-- mydata.lua local _M = {} local data = { dog = 3, cat = 4, pig = 5, } function _M.get_age(name) return data[name] end return _Mlocation /lua { content_by_lua_block { local mydata = require "mydata" ngx.say(mydata.get_age("dog")) } }这里
mydata就是一个模块,它只会被 worker 进程加载一次,之后,这个 worker 处理的所有请求,都会共享mydata模块的代码和数据。mydata模块中的data这个变量,就是模块级别的变量缺点:一般我们只用这种方式来保存只读的数据。写操作,可能会有 race condition,是非常难以定位的 bug。
例子:
-- mydata.lua local _M = {} local data = { dog = 3, cat = 4, pig = 5, } function _M.incr_age(name) data[name] = data[name] + 1 return data[name] end return _Mincr_age函数会对 data 这个表的数据进行修改。调用代码中增加
ngx.sleep(5),这个 sleep 是一个 yield 操作:location /lua { content_by_lua_block { local mydata = require "mydata" ngx.say(mydata. incr_age("dog")) ngx.sleep(5) -- yield API ngx.say(mydata. incr_age("dog")) } }如果没有 sleep(也可以是其他的非阻塞 IO 操作,比如访问 Redis 等),就不会有 yield 操作,也就不会产生竞争,那么,最后输出的数字就是顺序的。
但是有这个代码,在 sleep 的 5 秒钟内,很可能就有其他请求调用了
mydata.incr_age函数,修改了变量的值,从而导致最后输出的数字不连续。 -
用 shared dict 来共享数据,这些数据可以在多个 worker 之间共享。
它是基于红黑树实现的,性能很好,但也有局限性
-
必须事先在 Nginx 的配置文件中,声明共享内存的大小,并且这不能在运行期更改:
lua_shared_dict dogs 10m; -
只能缓存字符串类型的数据,不支持复杂的 Lua 数据类型。如果存放复杂数据类型,需要使用 JSON 等的序列化和反序列化,带来一些性能损耗。
-
共享字典
它对外提供了 20 多个 Lua API,不过所有的这些 API 都是原子操作,你不用担心多个 worker 和高并发的情况下的竞争问题。文档。
字典读写类
$ resty --shdict='dogs 1m' -e 'local dict = ngx.shared.dogs
dict:set("Tom", 56)
print(dict:get("Tom"))'其它写入方法:safe_set、add、safe_add、replace
这里safe 前缀的含义是,在内存占满的情况下,不根据 LRU 淘汰旧的数据,而是写入失败并返回 no memory 的错误信息。
其它读取数据的方法:get_stale相比 get 方法,它多了一个过期数据的返回值:
value, flags, stale = ngx.shared.DICT:get_stale(key)你还可以调用 delete 方法来删除指定的 key,它和 set(key, nil) 是等价的。
队列操作类
队列中的每一个元素,都用 ngx_http_lua_shdict_list_node_t 来描述:
typedef struct {
ngx_queue_t queue;
uint32_t value_len;
uint8_t value_type;
u_char data[1];
} ngx_http_lua_shdict_list_node_t;队列操作 API 的 PR 。
下面这 5 个队列 API,在文档中并没有对应的代码示例,可以在测试案例中找到对应的代码(145-shdict-list.t):
- lpush/rpush,表示在队列两端增加元素;
- lpop/rpop,表示在队列两端弹出元素;
- llen,表示返回队列的元素数量。
=== TEST 1: lpush & lpop
--- http_config
lua_shared_dict dogs 1m;
--- config
location = /test {
content_by_lua_block {
local dogs = ngx.shared.dogs
local len, err = dogs:lpush("foo", "bar")
if len then
ngx.say("push success")
else
ngx.say("push err: ", err)
end
local val, err = dogs:llen("foo")
ngx.say(val, " ", err)
local val, err = dogs:lpop("foo")
ngx.say(val, " ", err)
local val, err = dogs:llen("foo")
ngx.say(val, " ", err)
local val, err = dogs:lpop("foo")
ngx.say(val, " ", err)
}
}
--- request
GET /test
--- response_body
push success
1 nil
bar nil
0 nil
nil nil
--- no_error_log
[error]管理类
对于管理需求,如:用户申请了 100M 的空间作为 shared dict,那么这 100M 是否够用呢?里面存放了多少 key?具体是哪些 key 呢?
OpenResty 的官方态度,是希望用户使用火焰图来解决。
后续提供了几个方法:
get_keys(max_count?),默认也只返回前 1024 个 key; max_count 为 0,返回所有 key。
capacity 返回共享内存的大小(也就是 lua_shared_dict 中配置的大小)
free_space 返回空闲页的字节数。(因为 shared dict 是按照页来分配的,即使 free_space 返回为 0,在已经分配的页面中也可能存在空间,所以它的返回值并不能代表共享内存实际被占用的情况。)
require "resty.core.shdict"
local cats = ngx.shared.cats
local capacity_bytes = cats:capacity()
local free_page_bytes = cats:free_space()cosocket
cosocket 是各种 lua-resty-* 非阻塞库的基础,使用它来支持用 Lua 快速连接各种外部的网络服务。
早期连接 Redis、memcached 这些服务,需要使用 redis2-nginx-module、redis-nginx-module 和 memc-nginx-module这些 C 模块。
cosocket 功能加入以后,它们都已经被 lua-resty-redis 和 lua-resty-memcached 替代。
什么是 cosocket?
cosocket = coroutine + socket。可以把 cosocket 翻译为“协程套接字”。
cosocket 不仅需要 Lua 协程特性的支持,也需要 Nginx 中非常重要的事件机制的支持,这两者结合在一起,最终实现了非阻塞网络 I/O。另外,cosocket 支持 TCP、UDP 和 Unix Domain Socket。
内部实现:
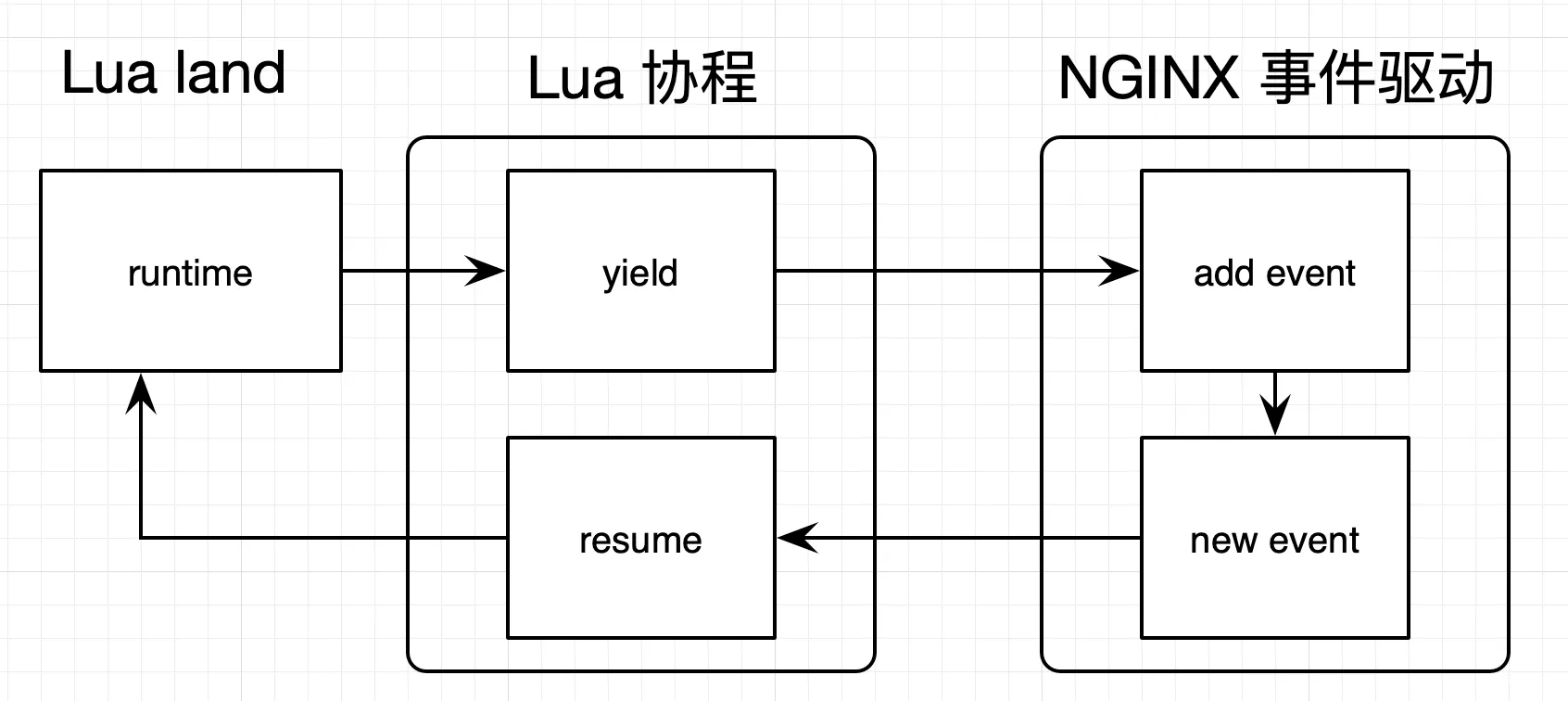
遇到网络 I/O 时,它会交出控制权(yield),把网络事件注册到 Nginx 监听列表中,并把权限交给 Nginx;当有 Nginx 事件达到触发条件时,便唤醒对应的协程继续处理(resume)。
OpenResty 正是以此为蓝图,封装实现 connect、send、receive 等操作,形成了如今见到的 cosocket API。
cosocket API 和指令简介
TCP 相关的 cosocket API 可以分为下面这几类。
- 创建对象:ngx.socket.tcp。
- 设置超时:tcpsock:settimeout 和 tcpsock:settimeouts。
- 建立连接:tcpsock:connect。
- 发送数据:tcpsock:send。
- 接受数据:tcpsock:receive、tcpsock:receiveany 和 tcpsock:receiveuntil。
- 连接池:tcpsock:setkeepalive。
- 关闭连接:tcpsock:close。
我们还要特别注意下,这些 API 可以使用的上下文:
rewrite*by_lua*, access*by_lua*, content_by_lua*, ngx.timer.*, ssl*certificate_by_lua*, ssl_session_fetch_by_lua\*\*这里我还要强调一点,归咎于 Nginx 内核的各种限制,cosocket API 在 set_by_lua*, log_by_lua*, header_filter_by_lua* 和 body_filter_by_lua* 中是无法使用的。而在 init_by_lua* 和 init_worker_by_lua* 中暂时也不能用,不过 Nginx 内核对这两个阶段并没有限制,后面可以增加对这它们的支持。
(突破 init_worker_by_lua 阶段调用 cosocket 限制方法 — ngx.timer)
此外,与这些 API 相关的,还有 8 个 lua_socket_ 开头的 Nginx 指令,我们简单来看一下。
lua_socket_connect_timeout:连接超时,默认 60 秒。lua_socket_send_timeout:发送超时,默认 60 秒。lua_socket_send_lowat:发送阈值(low water),默认为 0。lua_socket_read_timeout: 读取超时,默认 60 秒。lua_socket_buffer_size:读取数据的缓存区大小,默认 4k/8k。lua_socket_pool_size:连接池大小,默认 30。lua_socket_keepalive_timeout:连接池 cosocket 对象的空闲时间,默认 60 秒。lua_socket_log_errors:cosocket 发生错误时,是否记录日志,默认为 on。
这里你也可以看到,有些指令和 API 的功能一样的,比如设置超时时间和连接池大小等。不过,如果两者有冲突的话,API 的优先级高于指令,会覆盖指令设置的值。所以,一般来说,推荐使用 API 来做设置,这样也会更加灵活。
例子:
$ resty -e 'local sock = ngx.socket.tcp()
sock:settimeout(1000) -- one second timeout
local ok, err = sock:connect("www.baidu.com", 80)
if not ok then
ngx.say("failed to connect: ", err)
return
end
local req_data = "GET / HTTP/1.1\r\nHost: www.baidu.com\r\n\r\n"
local bytes, err = sock:send(req_data)
if err then
ngx.say("failed to send: ", err)
return
end
local data, err, partial = sock:receive()
if err then
ngx.say("failed to receive: ", err)
return
end
sock:close()
ngx.say("response is: ", data)'- 首先,通过
ngx.socket.tcp(),创建 TCP 的 cosocket 对象,名字是 sock。 - 然后,使用
settimeout(),把超时时间设置为 1 秒。注意这里的超时没有区分 connect、receive,是统一的设置。 - 接着,使用
connect()去连接指定网站的 80 端口,如果失败就直接退出。 - 连接成功的话,就使用
send()来发送构造好的数据,如果发送失败就退出。 - 发送数据成功的话,就使用
receive()来接收网站返回的数据。这里receive()的默认参数值是*l,也就是只返回第一行的数据;如果参数设置为了*a,就是持续接收数据,直到连接关闭; - 最后,调用
close(),主动关闭 socket 连接。
相似的函数:
-
settimeout(),作用是把超时时间统一设置为一个值。settimeouts()函数,分开设置超时时间(注意单位,虽然 OpenResty 和 lua-resty 库中大部分和时间相关 API 单位都是秒,这里是例外):sock:settimeouts(1000, 2000, 3000)这行代码表示连接超时为 1 秒,发送超时为 2 秒,读取超时为 3 秒。
-
receive()接口可以接收一行数据,也可以持续接收数据。receiveany()只接收指定大小的数据:local data, err, partial = sock:receiveany(10240)这段代码就表示,最多只接收 10K 的数据。
receiveuntil()一直获取数据,直到遇到指定字符串才停止。 如下:在循环中分段读取匹配到的数据,当读取完毕时,返回 nil。local reader = sock:receiveuntil("\r\n") while true do local data, err, partial = reader(4) if not data then if err then ngx.say("failed to read the data stream: ", err) break end ngx.say("read done") break end ngx.say("read chunk: [", data, "]") end这段代码中的
receiveuntil会返回\r\n之前的数据,并通过迭代器每次读取其中的 4 个字节。 -
setkeepalive()不直接关闭 socket,放入连接池。local ok, err = sock:setkeepalive(2 * 1000, 100) if not ok then ngx.say("failed to set reusable: ", err) end这段代码设置了连接的空闲时间为 2 秒,连接池的大小为 100。这样,在调用
connect()函数时,就会优先从连接池中获取 cosocket 对象。需要注意:
-
不能把发生错误的连接放入连接池,否则下次使用时,就会导致收发数据失败。这也是为什么需要判断每一个 API 调用是否成功的一个原因。
-
要搞清楚连接的数量。连接池是 worker 级别的,每个 worker 都有自己的连接池。所以,如果你有 10 个 worker,连接池大小设置为 30,那么对于后端的服务来讲,就等于有 300 个连接。
-
特权进程和定时任务
定时任务
OpenResty 提供了 ngx.timer来实现在后台定期地执行某些任务。
可以把ngx.timer ,看作是 OpenResty 模拟的客户端请求,用以触发对应的回调函数。
OpenResty 的定时任务可以分为两种:
ngx.timer.at,用来执行一次性的定时任务;ngx.time.every,用来执行固定周期的定时任务。
如何突破 init_worker_by_lua 中不能使用 cosocket 的限制?使用ngx.timer。
下面这段代码,就是启动了一个延时为 0 的定时任务。它启动了回调函数 handler,并在这个函数中,用 cosocket 去访问一个网站:
init_worker_by_lua_block {
local function handler()
local sock = ngx.socket.tcp()
local ok, err = sock:connect(“www.baidu.com", 80)
end
local ok, err = ngx.timer.at(0, handler)
}ngx.time.every API,执行周期性任务,更加接近 crontab 的解决方案。
缺点:在启动了一个 timer 之后,你就再也没有机会来取消这个定时任务了,ngx.timer.cancel 还在 TODO 中。 这个可能可作为替代?
OpenResty 提供了 lua_max_pending_timers 和 lua_max_running_timers 这两个指令,来对其进行限制。前者代表等待执行的定时任务的最大值,后者代表当前正在运行的定时任务的最大值。
获取当前等待执行的数量
content_by_lua_block {
ngx.timer.at(3, function() end)
ngx.say(ngx.timer.pending_count())
}这段代码会打印出 1,表示有 1 个计划任务正在等待被执行。
content_by_lua_block {
ngx.timer.at(0.1, function() ngx.sleep(0.3) end)
ngx.sleep(0.2)
ngx.say(ngx.timer.running_count())
}这段代码会打印出 1,表示有 1 个计划任务正在运行中。
特权进程
使用 lua-resty-core 中提供的 process.type API ,获取到进程的类型。
$ resty -e 'local process = require "ngx.process"
ngx.say("process type:", process.type())'
process type:single它返回的结果不是 worker, 而是 single。这意味 resty 启动的 Nginx 只有 worker 进程,没有 master 进程。
在 resty 的实现中,确实关闭了 master 进程:
master_process off;而 OpenResty 在 Nginx 的基础上进行了扩展,增加了特权进程:privileged agent。特权进程很特别:
- 它不监听任何端口,这就意味着不会对外提供任何服务;
- 它拥有和 master 进程一样的权限,一般来说是
root用户的权限,这就让它可以做很多 worker 进程不可能完成的任务; - 特权进程只能在
init_by_lua上下文中开启; - 另外,特权进程只有运行在
init_worker_by_lua上下文中才有意义,因为没有请求触发,也就不会走到content、access等上下文去。
开启特权进程的示例:
init_by_lua_block {
local process = require "ngx.process"
local ok, err = process.enable_privileged_agent()
if not ok then
ngx.log(ngx.ERR, "enables privileged agent failed error:", err)
end
}通过这段代码开启特权进程后,再去启动 OpenResty 服务,可以看到,Nginx 的进程中多了特权进程:
nginx: master process
nginx: worker process
nginx: privileged agent process使用 ngx.timer ,周期性地触发:
init_worker_by_lua_block {
local process = require "ngx.process"
local function reload(premature)
local f, err = io.open(ngx.config.prefix() .. "/logs/nginx.pid", "r")
if not f then
return
end
local pid = f:read()
f:close()
os.execute("kill -HUP " .. pid)
end
if process.type() == "privileged agent" then
local ok, err = ngx.timer.every(5, reload)
if not ok then
ngx.log(ngx.ERR, err)
end
end
}上面这段代码,实现了每 5 秒给 master 进程发送 HUP 信号量的功能。
自然,你也可以在此基础上实现更多有趣的功能,比如轮询数据库,看是否有特权进程的任务并执行。因为特权进程是 root 权限,这显然就有点儿“后门”程序的意味了。
当然普通用户启动,master 就是普通用户的权限 :)
特权进程的使用场景:一般用特权进程来处理的是清理日志、重启 OpenResty 自身等需要高权限的任务。
不要把 worker 进程的任务交给特权进程来处理。
非阻塞的 ngx.pipe
前面示例中的执行外部命令代码是阻塞的:
os.execute("kill -HUP " .. pid)lua-resty-shell 调用命令行就是非阻塞的
$ resty -e 'local shell = require "resty.shell"
local ok, stdout, stderr, reason, status =
shell.run([[echo "hello, world"]])
ngx.say(stdout)lua-resty-shell 的底层实现,依赖了 lua-resty-core 中的 [ngx.pipe] API,所以,这个使用 lua-resty-shell 打印出 hello wrold 的示例,改用 ngx.pipe ,可以写成下面这样:
$ resty -e 'local ngx_pipe = require "ngx.pipe"
local proc = ngx_pipe.spawn({"echo", "hello world"})
local data, err = proc:stdout_read_line()
ngx.say(data)'案例:实现 Memcached Server
memcached 的协议可以支持 TCP 和 UDP,这里我选择 TCP,下面是 get 和 set 命令的具体协议:
Get
根据 key 获取 value
Telnet command: get <key>\*\r\n
示例:
get key
VALUE key 0 4 data END
Set
存储键值对到 memcached 中
Telnet command:set <key> <flags> <exptime> <bytes> [noreply]\r\n<value>\r\n
示例:
set key 0 900 4 data
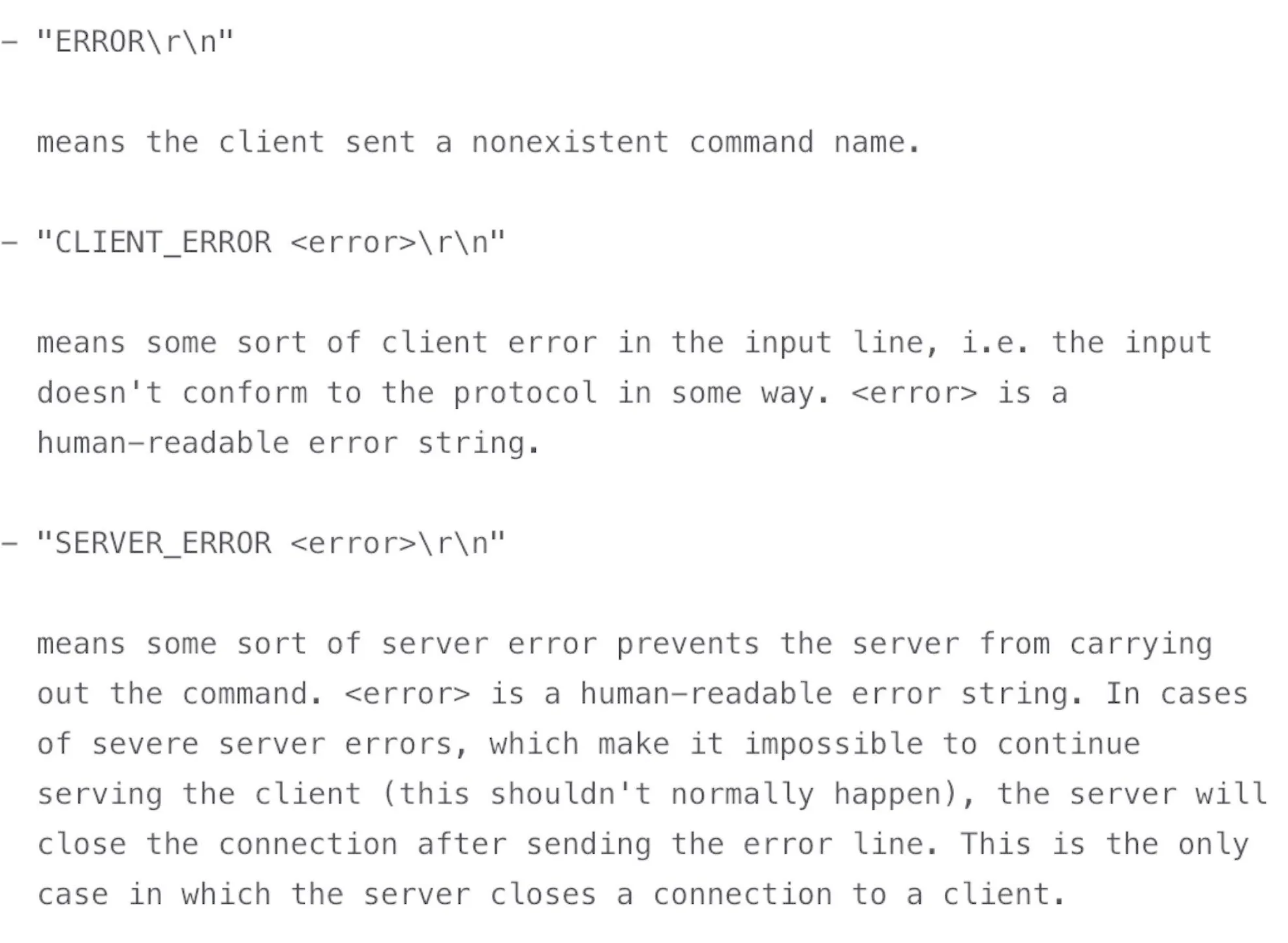
STORED下图出自 memcached 的文档,描述了出错的时候,应该返回什么内容和具体的格式
使用 shared dict 来模拟 memcached
构造测试用例
$ resty -e 'local memcached = require "resty.memcached"
local memc, err = memcached:new()
memc:set_timeout(1000) -- 1 sec
local ok, err = memc:connect("127.0.0.1", 11212)
local ok, err = memc:set("dog", 32)
if not ok then
ngx.say("failed to set dog: ", err)
return
end
local res, flags, err = memc:get("dog")
ngx.say("dog: ", res)'这段测试代码,使用 lua-rety-memcached 客户端库发起 connect 和 set 操作,并假设 memcached 的服务端监听本机的 11212 端口。
搭建框架
stream {
lua_shared_dict memcached 100m;
lua_package_path 'lib/?.lua;;';
server {
listen 11212;
content_by_lua_block {
local m = require("resty.memcached.server")
m.run()
}
}
}上面是 Nginx 配置文件,可以看出:
-
代码运行在 Nginx 的 stream 上下文中,而非 HTTP 上下文中,并且监听了 11212 端口;
-
shared dict 的名字为 memcached,大小是 100M,这些在运行期是不可以修改的;
-
另外,代码所在目录为
lib/resty/memcached, 文件名为server.lua, 入口函数为run(),这些信息你都可以从lua_package_path和content_by_lua_block中找到。
local new_tab = require "table.new"
local str_sub = string.sub
local re_find = ngx.re.find
local mc_shdict = ngx.shared.memcached
local _M = { _VERSION = '0.01' }
local function parse_args(s, start)
end
function _M.get(tcpsock, keys)
end
function _M.set(tcpsock, res)
end
function _M.run()
local tcpsock = assert(ngx.req.socket(true))
while true do
tcpsock:settimeout(60000) -- 60 seconds
local data, err = tcpsock:receive("*l")
local command, args
if data then
local from, to, err = re_find(data, [[(\S+)]], "jo")
if from then
command = str_sub(data, from, to)
args = parse_args(data, to + 1)
end
end
if args then
local args_len = #args
if command == 'get' and args_len > 0 then
_M.get(tcpsock, args)
elseif command == "set" and args_len == 4 then
_M.set(tcpsock, args)
end
end
end
end
return _M这段代码,便实现了入口函数 run() 的主要逻辑。没有做异常处理,依赖的 parse_args、get 和 set 也都是空函数,大致的框架已经出来了。
填充代码
根据 memcached 的协议文档,解析 memcached 命令的参数:
local function parse_args(s, start)
local arr = {}
while true do
local from, to = re_find(s, [[\S+]], "jo", {pos = start})
if not from then
break
end
table.insert(arr, str_sub(s, from, to))
start = to + 1
end
return arr
endget 函数,它可以一次查询多个键
function _M.get(tcpsock, keys)
local reply = ""
for i = 1, #keys do
local key = keys[i]
local value, flags = mc_shdict:get(key)
if value then
local flags = flags or 0
reply = reply .. "VALUE" .. key .. " " .. flags .. " " .. #value .. "\r\n" .. value .. "\r\n"
end
end
reply = reply .. "END\r\n"
tcpsock:settimeout(1000) -- one second timeout
local bytes, err = tcpsock:send(reply)
end其实,这里最核心的代码只有一行:local value, flags = mc_shdict:get(key),也就是从 shared dict 中查询到数据;至于其余的代码,都在按照 memcached 的协议拼接字符串,并最终 send 到客户端。
set 函数,它将接收到的参数转换为 shared dict API 的格式,把数据储存了起来
function _M.set(tcpsock, res)
local reply = ""
local key = res[1]
local flags = res[2]
local exptime = res[3]
local bytes = res[4]
local value, err = tcpsock:receive(tonumber(bytes) + 2)
if str_sub(value, -2, -1) == "\r\n" then
local succ, err, forcible = mc_shdict:set(key, str_sub(value, 1, bytes), exptime, flags)
if succ then
reply = reply .. “STORED\r\n"
else
reply = reply .. "SERVER_ERROR " .. err .. “\r\n”
end
else
reply = reply .. "ERROR\r\n"
end
tcpsock:settimeout(1000) -- one second timeout
local bytes, err = tcpsock:send(reply)
end