- OpenResty 学习笔记(目录)
- OpenResty 学习笔记(2) - 前置知识
- OpenResty 学习笔记(3) - LuaJIT
- OpenResty 学习笔记(4) - OpenResty 原理和 API
- OpenResty 学习笔记(5) - shared dict、cosocket、特权进程
- OpenResty 学习笔记(6) - 测试工具
- OpenResty 学习笔记(7) - 性能优化和编码指南
- OpenResty 学习笔记(8) - 动态调试
目录
LuaJIT
LuaJIT 在 OpenResty 整体架构中的位置:
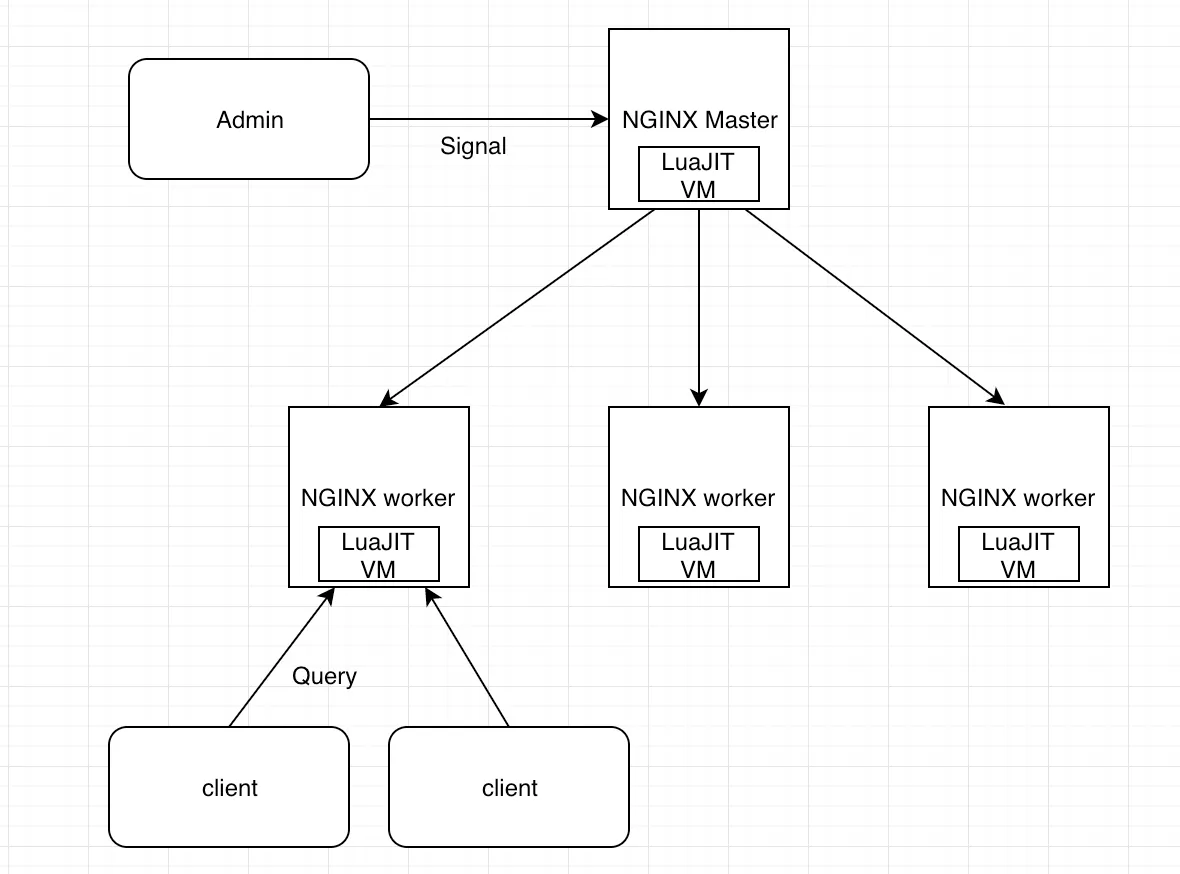
OpenResty 的 worker 进程都是 fork master 进程而得到的, 其实, master 进程中的 LuaJIT 虚拟机也会一起 fork 过来。在同一个 worker 内的所有协程,都会共享这个 LuaJIT 虚拟机,Lua 代码的执行也是在这个虚拟机中完成的。
标准 Lua 和 LuaJIT 的关系
**标准 Lua 和 LuaJIT 是两回事儿,LuaJIT 只是兼容了 Lua 5.1 的语法。**并对 Lua 5.2 和 5.3 做了选择性支持。
OpenResty 并没有直接使用 LuaJIT 官方提供的版本,而是在此基础上,扩展了自己的 fork: [openresty-luajit2]:
OpenResty 维护了自己的 LuaJIT 分支,并扩展了很多独有的 API。
后面提到的 LuaJIT,特指 OpenResty 自己维护的 LuaJIT 分支。
LuaJIT 优势
其实标准 Lua 出于性能考虑,也内置了虚拟机,所以 Lua 代码并不是直接被解释执行的,而是先由 Lua 编译器编译为字节码(Byte Code),然后再由 Lua 虚拟机执行。
而 LuaJIT 的运行时环境,除了一个汇编实现的 Lua 解释器外,还有一个可以直接生成机器代码的 JIT 编译器。开始的时候,LuaJIT 和标准 Lua 一样,Lua 代码被编译为字节码,字节码被 LuaJIT 的解释器解释执行。
但不同的是,LuaJIT 的解释器会在执行字节码的同时,记录一些运行时的统计信息,比如每个 Lua 函数调用入口的实际运行次数,还有每个 Lua 循环的实际执行次数。当这些次数超过某个随机的阈值时,便认为对应的 Lua 函数入口或者对应的 Lua 循环足够热,这时便会触发 JIT 编译器开始工作。
JIT 编译器会从热函数的入口或者热循环的某个位置开始,尝试编译对应的 Lua 代码路径。编译的过程,是把 LuaJIT 字节码先转换成 LuaJIT 自己定义的中间码(IR),然后再生成针对目标体系结构的机器码。
所以,所谓 LuaJIT 的性能优化,本质上就是让尽可能多的 Lua 代码可以被 JIT 编译器生成机器码,而不是回退到 Lua 解释器的解释执行模式。
Lua 奇怪语法
1. Lua 的下标从 1 开始
$ resty -e 't={100}; ngx.say(t[0])'正常会期望打印出 100,或者报错说下标 0 不存在。其实什么都不会打印,也不会报错(我使用的 LuaJIT 2.1.ROLLING — Copyright (C) 2005-2023 版本会有 [warn] 日志)。
$ resty -e 't={100};ngx.say(type(t[0]))'
nil得到的是空值。
下标不从 1 开始的特例:
ffi.new创建的数组ngx.worker.id返回的值
2. 使用 .. 来拼接字符串
不是使用 + 拼接
$ resty -e "ngx.say('hello' .. ', world')"
hello, world3. 只有 table 这一种数据结构
它里面可以包括数组和哈希表:
local color = {first = "red", "blue", third = "green", "yellow"}
print(color["first"]) --> output: red
print(color[1]) --> output: blue
print(color["third"]) --> output: green
print(color[2]) --> output: yellow
print(color[3]) --> output: nil如果不显式地用 键值对 的方式赋值,table 就会默认用数字作为下标,从 1 开始。所以 color[1] 就是 blue。
另外,想在 table 中获取到正确长度,也是一件不容易的事情,我们来看下面这些例子:
local t1 = { 1, 2, 3 }
print("Test1 " .. table.getn(t1))
local t2 = { 1, a = 2, 3 }
print("Test2 " .. table.getn(t2))
local t3 = { 1, nil }
print("Test3 " .. table.getn(t3))
local t4 = { 1, nil, 2 }
print("Test4 " .. table.getn(t4))使用 resty 运行的结果如下:
Test1 3
Test2 2
Test3 1
Test4 1除了第一个返回长度为 3 的测试案例外,后面的测试都是我们预期之外的结果。
事实上,想要在 Lua 中获取 table 长度,必须注意到,只有在 table 是 序列 的时候,才能返回正确的值。
序列是数组(array)的子集,也就是说,table 中的元素都可以用正整数下标访问到,不存在键值对的情况。对应到上面的代码中,除了 t2 外,其他的 table 都是 array。
其次,序列中不包含空洞(hole),即 nil。综合这两点来看,上面的 table 中, t1 是一个序列,而 t3 和 t4 是 array,却不是序列(sequence)。
到这里,你可能还有一个疑问,为什么 t4 的长度会是 1 呢?其实这是因为,在遇到 nil 时,获取长度的逻辑就不继续往下运行,而是直接返回了。
4. 默认是全局变量
除非相当确定,否则在 Lua 中声明变量时,前面都要加上 local:
local s = 'hello'在 Lua 中,变量默认是全局的,会被放到名为 _G 的 table 中。不加 local 的变量会在全局表中查找,这是昂贵的操作。如果再加上一些变量名的拼写错误,就会造成难以定位的 bug。
强烈建议总是使用 local 来声明变量,即使在 require module 的时候也是一样。
-- Recommended
local xxx = require('xxx')
-- Avoid
require('xxx')LuaJIT FFI(Foreign Function Interface)调用外部的 C 函数和使用 C 的数据结构
local ffi = require("ffi")
ffi.cdef[[
int printf(const char *fmt, ...);
]]
ffi.C.printf("Hello %s!", "world")lua-resty-core
在 Lua 中,你可以用 Lua C API 来调用 C 函数,而在 LuaJIT 中还可以使用 FFI。对 OpenResty 而言:
- 在核心的
lua-nginx-module中,调用 C 函数的 API,都是使用 Lua C API 来完成的; - 而在
lua-resty-core中,则是把lua-nginx-module已有的部分 API,使用 FFI 的模式重新实现了一遍。
以下以 ngx.base64_decode 为例,直观认识 Lua C API 和 FFI 的实现有何不同
Lua CFunction
lua-nginx-module 中用 Lua C API 是如何实现的。我们在项目的代码中搜索 decode_base64,可以找到它的代码实现在 ngx_http_lua_string.c 中
lua_pushcfunction(L, ngx_http_lua_ngx_decode_base64);
lua_setfield(L, -2, "decode_base64");这里注册了一个 CFunction:ngx_http_lua_ngx_decode_base64, 而它与 ngx.base64_decode 这个对外暴露的 API 是对应关系。
继续在这个 C 文件中搜索 ngx_http_lua_ngx_decode_base64,它定义在文件的开始位置:
static int ngx_http_lua_ngx_decode_base64(lua_State *L);对于那些能够被 Lua 调用的 C 函数来说,它的接口必须遵循 Lua 要求的形式,也就是 typedef int (*lua_CFunction)(lua_State* L)。它包含的参数是 lua_State 类型的指针 L ;它的返回值类型是一个整型,表示返回值的数量,而非返回值自身。
它的实现如下(这里去掉了错误处理的代码):
static int
ngx_http_lua_ngx_decode_base64(lua_State *L)
{
ngx_str_t p, src;
src.data = (u_char *) luaL_checklstring(L, 1, &src.len);
p.len = ngx_base64_decoded_length(src.len);
p.data = lua_newuserdata(L, p.len);
if (ngx_decode_base64(&p, &src) == NGX_OK) {
lua_pushlstring(L, (char *) p.data, p.len);
} else {
lua_pushnil(L);
}
return 1;
}这段代码中,最主要的是 ngx_base64_decoded_length 和 ngx_decode_base64, 它们都是 NGINX 自身提供的 C 函数。
我们知道,用 C 编写的函数,无法把返回值传给 Lua 代码,而是需要通过栈,来传递 Lua 和 C 之间的调用参数和返回值。这也是为什么,会有很多我们一眼无法看懂的代码。同时,这些代码也不能被 JIT 跟踪到,所以对于 LuaJIT 而言,这些操作是处于黑盒中的,没法进行优化。
LuaJIT FFI
而 FFI 则不同。FFI 的交互部分是用 Lua 实现的,这部分代码可以被 JIT 跟踪到,并进行优化;当然,代码也会更加简洁易懂。
我们还是以 base64_decode为例,它的 FFI 实现分散在两个仓库中: lua-resty-core 和 lua-nginx-module。我们先来看下前者里面实现的代码:
ngx.decode_base64 = function (s)
local slen = #s
local dlen = base64_decoded_length(slen)
local dst = get_string_buf(dlen)
local pdlen = get_size_ptr()
local ok = C.ngx_http_lua_ffi_decode_base64(s, slen, dst, pdlen)
if ok == 0 then
return nil
end
return ffi_string(dst, pdlen[0])
end你会发现,相比 CFunction,FFI 实现的代码清爽了很多,它具体的实现是 lua-nginx-module 仓库中的ngx_http_lua_ffi_decode_base64
int
ngx_http_lua_ffi_decode_base64(const u_char *src, size_t slen, u_char *dst,
size_t *dlen)
{
ngx_int_t rc;
ngx_str_t in, out;
in.data = (u_char *) src;
in.len = slen;
out.data = dst;
rc = ngx_decode_base64(&out, &in);
*dlen = out.len;
return rc == NGX_OK;
}OpenResty 中的函数都是有命名规范的,你可以通过命名推测出它的用处。比如:
ngx_http_lua_ffi_,是用 FFI 来处理 NGINX HTTP 请求的 Lua 函数;ngx_http_lua_ngx_,是用 Cfunction 来处理 NGINX HTTP 请求的 Lua 函数;- 其他
ngx_和lua_开头的函数,则分别属于 NGINX 和 Lua 的内置函数。
FFI 更多的 API 和细节:LuaJIT 官方的教程 和 文档。
LuaJIT FFI GC
在 FFI 中申请的内存,到底由谁来管理呢?是应该我们在 C 里面手动释放,还是 LuaJIT 自动回收呢?
这里有个简单的原则:LuaJIT 只负责由自己分配的资源;而 ffi.C 是 C 库的命名空间,所以,使用 ffi.C 分配的空间不由 LuaJIT 负责,需要你自己手动释放。
举个例子,比如你使用 ffi.C.malloc 申请了一块内存,那你就需要用配对的 ffi.C.free 来释放。LuaJIT 的官方文档中有一个对应的示例:
local p = ffi.gc(ffi.C.malloc(n), ffi.C.free)
...
p = nil -- Last reference to p is gone.
-- GC will eventually run finalizer: ffi.C.free(p)这段代码中,ffi.C.malloc(n) 申请了一段内存,同时 ffi.gc 就给它注册了一个析构的回调函数 ffi.C.free。这样一来,p 这个 cdata 在被 LuaJIT GC 的时候,就会自动调用 ffi.C.free,来释放 C 级别的内存。而 cdata 是由 LuaJIT 负责 GC 的 ,所以上述代码中的 p 会被 LuaJIT 自动释放。
这里要注意,如果你要在 OpenResty 中申请大块的内存,更推荐你用 ffi.C.malloc 而不是 ffi.new。原因也很明显:
ffi.new返回的是一个cdata,这部分内存由 LuaJIT 管理;- LuaJIT GC 的管理内存是有上限的,OpenResty 中的 LuaJIT 并未开启 GC64 选项,所以单个 worker 内存的上限只有 2G。一旦超过 LuaJIT 的内存管理上限,就会导致报错。
在使用 FFI 的时候,我们还需要特别注意内存泄漏的问题。
检测内存泄漏的工具:Valgrind
OpenResty 的 CLI resty 也有 --valgrind 选项
OpenResty 提供基于 systemtap 的扩展,来对 OpenResty 程序进行活体的动态分析。你可以在这个项目的工具集中,搜索 gc 这个关键字,会看到 lj-gc 和 lj-gc-objs 这两个工具。
而对于 core dump 这种离线分析,OpenResty 提供了 GDB 的工具集,同样你可以在里面搜索 gc,找到 lgc、lgcstat 和 lgcpath 三个工具。
lua-resty-core
lua-resty-core 中不仅重新实现了部分 lua-nginx-module 项目中的 API,比如 ngx.re.match、ngx.md5 等,还实现了不少新的 API,比如 ngx.ssl、ngx.base64、ngx.errlog、ngx.process、ngx.re.split、ngx.resp.add_header、ngx.balancer、ngx.semaphore 等等。
NYI(Not Yet Implemented)
FFI 虽然好,却也并不是性能银弹。它之所以高效,主要原因就是可以被 JIT 追踪并优化。如果你写的 Lua 代码不能被 JIT,而是需要在解释模式下执行,那么 FFI 的效率反而会更低。
LuaJIT 的运行时环境,除了一个汇编实现的 Lua 解释器外,还有一个可以直接生成机器代码的 JIT 编译器。
LuaJIT 中 JIT 编译器的实现还不完善,有一些原语它还无法编译,因为这些原语实现起来比较困难,再加上 LuaJIT 的作者目前处于半退休状态。这些原语包括常见的 pairs() 函数、unpack() 函数、基于 Lua CFunction 实现的 Lua C 模块等。这样一来,当 JIT 编译器在当前代码路径上遇到它不支持的操作时,便会退回到解释器模式。
而 JIT 编译器不支持的这些原语, 就是 NYI,全称为 Not Yet Implemented。LuaJIT 的官网上有这些 NYI 的完整列表
如何理解这个表格?

string.byte对应的能否被编译的状态是yes,表明可以被 JIT,可以放心大胆地在代码中使用。string.char对应的编译状态是2.1,表明从 LuaJIT 2.1 开始支持。我们知道,OpenResty 中的 LuaJIT 是基于 LuaJIT 2.1 的,所以也可以放心使用。string.dump对应的编译状态是never,即不会被 JIT,会退回到解释器模式。目前来看,未来也没有计划支持这个原语。string.find对应的编译状态是2.1 partial,意思是从 LuaJIT 2.1 开始部分支持,后面的备注中写的是只支持搜索固定的字符串,不支持模式匹配。所以对于固定字符串的查找,你使用string.find是可以被 JIT 的。
NYI 的替代方案
1.string.gsub() 函数
第一个我们来看 string.gsub() 函数。它是 Lua 内置的字符串操作函数,作用是做全局的字符串替换,比如下面这个例子:
$ resty -e 'local new = string.gsub("banana", "a", "A"); print(new)'
bAnAnA这个函数是一个 NYI 原语,无法被 JIT 编译。
如何寻找替代函数:
在平时开发中,可以常开 lua-nginx-module 的 GitHub 文档页面。
对刚刚的这个例子,我们可以用 gsub 作为关键字,在文档页面中搜索,可以找到 ngx.re.gsub
newstr, n, err = ngx.re.gsub(subject, regex, replace, options?)
对于不熟悉 OpenResty 正则体系的工程师而言,看到最后的变参 options ,你可能会比较困惑。不过,这个变参的解释,并不在此函数中,而是在 ngx.re.match 函数的文档中。
通过查看参数 options 的文档,你会发现,只要我们把它设置为 jo,就开启了 PCRE 的 JIT。这样,使用 ngx.re.gsub 的代码,既可以被 LuaJIT 进行 JIT 编译,也可以被 PCRE JIT 进行 JIT 编译。
2.string.find() 函数
和 string.gsub 不同的是,string.find 在 plain 模式(即固定字符串的查找)下,是可以被 JIT 的;而带有正则这种的字符串查找,string.find 并不能被 JIT ,这时就要换用 OpenResty 自己的 API,也就是 ngx.re.find 来完成。
所以,当你在 OpenResty 中做字符串查找时,首先一定要明确区分,你要查找的是固定的字符串,还是正则表达式。如果是前者,就要用 string.find,并且记得把最后的 plain 设置为 true:
string.find("foo bar", "foo", 1, true)如果是后者,你应该用 OpenResty 自己的 API,并开启 PCRE 的 JIT 选项:
ngx.re.find("foo bar", "^foo", "jo")其实,这里更适合做一层封装,并把优化选项默认打开,不要让最终的使用者知道这么多细节。
3.unpack() 函数
unpack() 也是要避免使用的函数,特别是不要在循环体中使用。你可以改用数组的下标去访问,比如下面代码的这个例子:
$ resty -e '
local a = {100, 200, 300, 400}
for i = 1, 2 do
print(unpack(a))
end'
$ resty -e 'local a = {100, 200, 300, 400}
for i = 1, 2 do
print(a[1], a[2], a[3], a[4])
end'用restydoc 来搜索一下:
$ restydoc -s unpack从 unpack 的文档中,你可以看出,unpack (list [, i [, j]]) 和 return list[i], list[i+1], , list[j] 是等价的,可以把 unpack 看成一个语法糖。这样,可以用数组下标的方式来访问,以免打断 LuaJIT 的 JIT 编译。
4.pairs() 函数
这个并没有等价的替代方案,你只能尽量避免使用,或者改用数字下标访问的数组,特别是在热代码路径上不要遍历哈希表。这里我解释一下代码热路径,它的意思是,这段代码会被返回执行很多次,比如在一个很大的循环里面。
总结:
要想规避 NYI 原语的使用,需要注意下面这两点:
- 请优先使用 OpenResty 提供的 API,而不是 Lua 的标准库函数。这里要牢记, Lua 是嵌入式语言,我们实际上是在 OpenResty 中编程,而不是 Lua。
- 如果万不得已要使用 NYI 原语,请一定确保它没有在代码热路径上。
如何检测 NYI?
方法一:
LuaJIT 自带的 jit.dump 和 jit.v 模块。它们都可以打印出 JIT 编译器工作的过程。前者会输出非常详细的信息,可以用来调试 LuaJIT 本身,你可以参考它的源码来做更深入的了解;后者的输出比较简单,每行对应一个 trace,通常用来检测是否可以被 JIT。
先在 init_by_lua 中,添加以下两行代码:
local v = require "jit.v"
v.on("/tmp/jit.log")然后,运行你自己的压力测试工具,或者跑几百个单元测试集,让 LuaJIT 足够热,触发 JIT 编译。这些都完成后,再来检查 /tmp/jit.log 的结果。
方法二:
简单验证的话, 使用 resty 就足够了
$resty -j v -e 'for i=1, 1000 do
local newstr, n, err = ngx.re.gsub("hello, world", "([a-z])[a-z]+", "[$0,$1]", "i")
end'
[TRACE 1 (command line -e):1 stitch C:107bc91fd]
[TRACE 2 (1/stitch) (command line -e):2 -> 1]其中,resty 的 -j 就是和 LuaJIT 相关的选项;后面的值为 dump 和 v,就对应着开启 jit.dump 和 jit.v 模式。
在 jit.v 模块的输出中,每一行都是一个成功编译的 trace 对象。刚刚是一个能够被 JIT 的例子,而如果遇到 NYI 原语,输出里面就会指明 NYI,比如下面这个 pairs 的例子:
$resty -j v -e 'local t = {}
for i=1,100 do
t[i] = i
end
for i=1, 1000 do
for j=1,1000 do
for k,v in pairs(t) do
--
end
end
end'它就不能被 JIT,所以结果里,指明了第 8 行中有 NYI 原语。
[TRACE 1 (command line -e):2 loop]
[TRACE --- (command line -e):7 -- NYI: bytecode 72 at (command line -e):8]table 和 metatable
LuaJIT 中只有 table 这一个数据结构,并没有区分开数组、哈希、集合等概念,而是揉在了一起。
local color = {first = "red", "blue", third = "green", "yellow"}
print(color["first"]) --> output: red
print(color[1]) --> output: blue
print(color["third"]) --> output: green
print(color[2]) --> output: yellow
print(color[3]) --> output: nil这个例子中, color 这个 table 包含了数组和哈希,并且可以互不干扰地进行访问。比如,你可以用 ipairs 函数,只遍历数组部分的内容:
$ resty -e 'local color = {first = "red", "blue", third = "green", "yellow"}
for k, v in ipairs(color) do
print(k)
end
'table 库函数
table.getn 获取元素个数
对于序列,用table.getn 或者一元操作符 # ,可以正确返回元素的个数。比如下面这个例子,就会返回我们预期中的 3。
$ resty -e 'local t = { 1, 2, 3 }
print(table.getn(t)) '而对于不是序列的 table,就无法返回正确的值。比如第二个例子,返回的就是 1。
$ resty -e 'local t = { 1, a = 2 }
print(#t) '所以在 OpenResty 的环境下,除非你明确知道,你正在获取序列的长度,否则请不要使用函数 table.getn 和一元操作符 # 。
另外,table.getn 和一元操作符 # 并不是 O(1) 的时间复杂度,而是 O(n) (这里可能不准确,lua5.4 最坏复杂度是是 O(lg(n), luajit 中可能是接近的)
table.remove 删除指定元素
在 table 中根据下标来删除元素
$ resty -e 'local color = {first = "red", "blue", third = "green", "yellow"}
table.remove(color, 1)
for k, v in pairs(color) do
print(v)
end'这段代码会把下标为 1 的 blue 删除掉。
如何删除 table 中的哈希部分呢?
把 key 对应的 value 设置为 nil 即可。这样,color这个例子中,third 对应的green就被删除了。
$ resty -e 'local color = {first = "red", "blue", third = "green", "yellow"}
color.third = nil
for k, v in pairs(color) do
print(v)
end'table.concat 元素拼接函数
它可以按照下标,把 table 中的元素拼接起来。因为是针对下标的操作,所以拼接只是针对 table 的数组部分。
$ resty -e 'local color = {first = "red", "blue", third = "green", "yellow"}
print(table.concat(color, ", "))'它输出的是 blue, yellow,哈希的部分被跳过了。
这个函数还可以指定下标的起始位置来做拼接,比如下面这样的写法:
$ resty -e 'local color = {first = "red", "blue", third = "green", "yellow", "orange"}
print(table.concat(color, ", ", 2, 3))'这次输出是 yellow, orange,跳过了 blue。
table.insert 插入一个元素
它可以下标插入一个新的元素,自然,影响的还是 table 的数组部分。
$ resty -e 'local color = {first = "red", "blue", third = "green", "yellow"}
table.insert(color, 1, "orange")
print(color[1])
'
orangetable.insert 虽然是一个很常见的操作,但性能并不乐观。如果你不是根据指定下标来插入元素,那么每次都需要调用 LuaJIT 的 lj_tab_len 来获取数组的长度,以便插入队尾。正如我们在 table.getn 中提到的,获取 table 长度的时间复杂度为 O(n) 。
所以,对于table.insert 操作,我们应该尽量避免在热代码中使用,比如:
local t = {}
for i = 1, 10000 do
table.insert(t, i)
endLuaJIT 的 table 扩展函数
table.new(narray, nhash) 新建 table
这个函数,会预先分配好指定的数组和哈希的空间大小,而不是在插入元素时自增长,这也是它的两个参数 narray 和 nhash 的含义。自增长是一个代价比较高的操作,会涉及到空间分配、resize 和 rehash 等,我们应该尽量避免。
table.new 在 GitHub 项目的扩展文档 中。
local new_tab = require "table.new"
local t = new_tab(100, 0)
for i = 1, 100 do
t[i] = i
end这段代码新建了一个 table,里面包含 100 个数组元素和 0 个哈希元素。
超出预设的空间大小,也可以正常使用,只不过性能会退化,也就失去了使用 table.new 的意义。
table.clear() 清空 table
它用来清空某个 table 里的所有数据,但并不会释放数组和哈希部分占用的内存。
所以,它在循环利用 Lua table 时非常有用,可以避免反复创建和销毁 table 的开销。
$ resty -e 'local clear_tab =require "table.clear"
local color = {first = "red", "blue", third = "green", "yellow"}
clear_tab(color)
for k, v in pairs(color) do
print(k)
end'OpenResty 的 table 扩展函数
OpenResty 自己维护的 LuaJIT 分支,也对 table 做了扩展,它新增了几个 API:table.isempty、table.isarray、 table.nkeys 和 table.clone。
用 table.nkeys 来举例说明下,它实际上是获取 table 长度的函数,返回的是 table 的元素个数,包括数组和哈希部分的元素。因此,我们可以用它来替代 table.getn,比如下面这样来用:
local nkeys = require "table.nkeys"
print(nkeys({})) -- 0
print(nkeys({ "a", nil, "b" })) -- 2
print(nkeys({ dog = 3, cat = 4, bird = nil })) -- 2
print(nkeys({ "a", dog = 3, cat = 4 })) -- 3元表
元表是 Lua 中独有的概念,在实际项目中的使用非常广泛,在几乎所有的 lua-resty-* 库中,都能看到它的身影。
元表的表现行为类似于操作符重载,比如我们可以重载 __add,来计算两个 Lua 数组的并集;或者重载 __tostring,来定义转换为字符串的函数。
而 Lua 提供了两个处理元表的函数:
- 第一个是
setmetatable(table, metatable), 用于为一个 table 设置元表; - 第二个是
getmetatable(table),用于获取 table 的元表。
$ resty -e ' local version = {
major = 1,
minor = 1,
patch = 1
}
version = setmetatable(version, {
__tostring = function(t)
return string.format("%d.%d.%d", t.major, t.minor, t.patch)
end
})
print(tostring(version))
'定义了一个 名为 version的 table,如果直接打印 version,只会输出这个 table 的地址。
print(tostring(version))这里使用 setmetatable自定义这个 table 的字符串转换函数,也就是 __tostring方法,就可以打印出版本号: 1.1.1。
在项目中, 还经常重载元表中的以下两个元方法(metamethod)。
1、__index 。在 table 中查找一个元素时,首先会直接从 table 中查询,如果没有找到,就继续到元表的 __index 中查询。
如下把 patch 从 version 这个 table 中去掉
$ resty -e ' local version = {
major = 1,
minor = 1
}
version = setmetatable(version, {
__index = function(t, key)
if key == "patch" then
return 2
end
end,
__tostring = function(t)
return string.format("%d.%d.%d", t.major, t.minor, t.patch)
end
})
print(tostring(version))
'这样,t.patch 其实获取不到值,那么就会走到 __index 这个函数中,结果就会打印出 1.1.2。
__index 不仅可以是一个函数,也可以是一个 table。如下代码等价于上面
$ resty -e ' local version = {
major = 1,
minor = 1
}
version = setmetatable(version, {
__index = {patch = 2},
__tostring = function(t)
return string.format("%d.%d.%d", t.major, t.minor, t.patch)
end
})
print(tostring(version))
'**2、__call。**它类似于仿函数,可以让 table 被调用。
$ resty -e '
local version = {
major = 1,
minor = 1,
patch = 1
}
local function print_version(t)
print(string.format("%d.%d.%d", t.major, t.minor, t.patch))
end
version = setmetatable(version,
{__call = print_version})
version()
'使用 setmetatable,给 version 这个 table 增加了元表,而里面的 __call 元方法指向了函数 print_version 。那么,如果我们尝试把 version 当作函数调用,这里就会执行函数 print_version。
而 getmetatable 是和 setmetatable 配对的操作,可以获取到已经设置的元表,比如下面这段代码:
$ resty -e ' local version = {
major = 1,
minor = 1
}
version = setmetatable(version, {
__index = {patch = 2},
__tostring = function(t)
return string.format("%d.%d.%d", t.major, t.minor, t.patch)
end
})
print(getmetatable(version).__index.patch)
'其它元方法:文档
面向对象
可以使用 metatable 来实现 OO。
lua-resty-mysql 是 OpenResty 官方的 MySQL 客户端,里面就使用元表模拟了类和类方法,它的使用方式如下所示:
$ resty -e 'local mysql = require "resty.mysql" -- 先引用 lua-resty 库
local db, err = mysql:new() -- 新建一个类的实例
db:set_timeout(1000) -- 调用类的方法'在调用类方法的时候,为什么是冒号而不是点号呢?
在这里冒号和点号都是可以的,db:set_timeout(1000) 和 db.set_timeout(db, 1000) 是完全等价的。冒号是 Lua 中的一个语法糖,可以省略掉函数的第一个参数 self。
local _M = { _VERSION = '0.21' } -- 使用 table 模拟类
local mt = { __index = _M } -- mt 即 metatable 的缩写,__index 指向类自身
-- 类的构造函数
function _M.new(self)
local sock, err = tcp()
if not sock then
return nil, err
end
return setmetatable({ sock = sock }, mt) -- 使用 table 和 metatable 模拟类的实例
end
-- 类的成员函数
function _M.set_timeout(self, timeout) -- 使用 self 参数,获取要操作的类的实例
local sock = self.sock
if not sock then
return nil, "not initialized"
end
return sock:settimeout(timeout)
end_M 这个 table 模拟了一个类,初始化时,它只有 _VERSION 这一个成员变量,并在随后定义了 _M.set_timeout 等成员函数。在 _M.new(self) 这个构造函数中,我们返回了一个 table,这个 table 的元表就是 mt,而 mt 的 __index 元方法指向了 _M,这样,返回的这个 table 就模拟了类 _M 的实例。
Lua 的独有概念和坑
弱表
弱表(weak table),是 Lua 中很独特的一个概念,和垃圾回收相关。Lua 是自动垃圾回收,但简单的引用计数还不太够用。
举个例子,我们把一个 Lua 的对象 Foo(table 或者函数)插入到 table tb 中,这就会产生对这个对象 Foo 的引用。即使没有其他地方引用 Foo,tb 对它的引用也还一直存在,那么 GC 就没有办法回收 Foo 所占用的内存。这时候,我们就只有两种选择:
- 一是手工释放
Foo; - 二是让它常驻内存。
$ resty -e 'local tb = {}
tb[1] = {red}
tb[2] = function() print("func") end
print(#tb) -- 2
collectgarbage()
print(#tb) -- 2
table.remove(tb, 1)
print(#tb) -- 1弱表,首先它是一个表,然后这个表里面的所有元素都是弱引用。
$ resty -e 'local tb = {}
tb[1] = {red}
tb[2] = function() print("func") end
setmetatable(tb, {__mode = "v"})
print(#tb) -- 2
collectgarbage()
print(#tb) -- 0
'可以看到,没有被使用的对象都被 GC 了。这其中,最重要的就是下面这一行代码:
setmetatable(tb, {__mode = "v"})当一个 table 的元表中存在 __mode 字段时,这个 table 就是弱表(weak table)了。
- 如果
__mode的值是k,那就意味着这个 table 的键是弱引用。 - 如果
__mode的值是v,那就意味着这个 table 的值是弱引用。 - 当然,你也可以设置为
kv,表明这个表的键和值都是弱引用。
这三者中的任意一种弱表,只要它的 键 或者 值 被回收了,那么对应的整个键值 对象都会被回收。
在上面的代码示例中,__mode 的值 v,而tb 是一个数组,数组的 value 则是 table 和函数对象,所以可以被自动回收。不过,如果你把__mode 的值改为 k,就不会 GC 了,比如看下面这段代码:
$ resty -e 'local tb = {}
tb[1] = {red}
tb[2] = function() print("func") end
setmetatable(tb, {__mode = "k"})
print(#tb) -- 2
collectgarbage()
print(#tb) -- 2
'请注意,这里我们只演示了 value 为弱引用的弱表,也就是数组类型的弱表。自然,你同样可以把对象作为 key,来构建哈希表类型的弱表,比如下面这样写:
$ resty -e 'local tb = {}
tb[{color = red}] = "red"
local fc = function() print("func") end
tb[fc] = "func"
fc = nil
setmetatable(tb, {__mode = "k"})
for k,v in pairs(tb) do
print(v)
end
collectgarbage()
print("----------")
for k,v in pairs(tb) do
print(v)
end
'
func
red
----------闭包和 upvalue
tb[2] = function() print("func") end其实就是把一个匿名函数,作为 table 的值给存储了起来。
在 Lua 中,下面这段代码中动两个函数的定义是完全等价的。不过注意,后者是把函数赋值给一个变量,这也是我们经常会用到的一种方式:
local function foo() print("foo") end
local foo = fuction() print("foo") endLua 支持把一个函数写在另外一个函数里面,即嵌套函数:
$ resty -e '
local function foo()
local i = 1
local function bar()
i = i + 1
print(i)
end
return bar
end
local fn = foo()
print(fn()) -- 2
'bar 这个函数可以读取函数 foo 里面的局部变量 i,并修改它的值,即使这个变量并不在 bar 里面定义。这个特性叫做词法作用域(lexical scoping)。
事实上,Lua 的这些特性正是闭包的基础。所谓闭包 ,简单地理解,它其实是一个函数,不过它访问了另外一个函数词法作用域中的变量。
Lua 的所有函数实际上都是闭包,即使你没有嵌套。这是因为 Lua 编译器会把 Lua 脚本外面,再包装一层主函数。比如下面这几行简单的代码段:
local foo, bar
local function fn()
foo = 1
bar = 2
end在编译后,就会变为下面的样子:
function main(...)
local foo, bar
local function fn()
foo = 1
bar = 2
end
endupvalue 就是 Lua 中独有的概念了。从字面意思来看,可以翻译成 上面的值。实际上,upvalue 就是闭包中捕获的自己词法作用域外的那个变量。
local foo, bar
local function fn()
foo = 1
bar = 2
end你可以看到,函数 fn 捕获了两个不在自己词法作用域的局部变量 foo 和 bar,而这两个变量,实际上就是函数 fn 的 upvalue。
常见的坑
下标从 0 开始还是从 1 开始
因为在 LuaJIT 中,使用 ffi.new 创建的数组,下标又是从 0 开始的:
local buf = ffi_new("char[?]", 128)所以,如果你要访问上面这段代码中 buf 这个 cdata,请记得下标从 0 开始,而不是 1。在使用 FFI 和 C 交互的时候,一定要特别注意这个地方。
正则模式匹配
OpenResty 中并行着两套字符串匹配方法:Lua 自带的 sting 库,以及 OpenResty 提供的 ngx.re.* API。
其中, Lua 正则模式匹配是自己独有的格式,和 PCRE 的写法不同。下面是一个简单的示例:
resty -e 'print(string.match("foo 123 bar", "%d%d%d"))' — 123这段代码从字符串中提取了数字部分,和我们熟悉的正则表达式完全不同。Lua 自带的正则匹配库,不仅代码维护成本高,而且性能低——不能被 JIT,而且被编译过一次的模式也不会被缓存。
使用 OpenResty 提供的 ngx.re 来替代。只有在查找固定字符串的时候,我们才考虑使用 plain 模式来调用 string 库。
在 OpenResty 中,我们总是优先使用 OpenResty 的 API,然后是 LuaJIT 的 API,使用 Lua 库则需要慎之又慎。
json 编码时无法区分 array 和 dict
json 编码时无法区分 array 和 dict。由于 Lua 中只有 table 这一个数据结构,所以在 json 对空 table 编码的时候,自然就无法确定编码为数组还是字典:
resty -e 'local cjson = require "cjson"
local t = {}
print(cjson.encode(t))
'它的输出是 {},由此可见, OpenResty 的 cjson 库,默认把空 table 当做字典来编码。当然,我们可以通过 encode_empty_table_as_object 这个函数,来修改这个全局的默认值:
resty -e 'local cjson = require "cjson"
cjson.encode_empty_table_as_object(false)
local t = {}
print(cjson.encode(t))
'空 table 就被编码为了数组:[]。
上面是全局设置,影响面大,局部设置方法:
-
把
cjson.empty_array这个 userdata 赋值给指定 table。这样,在 json 编码的时候,它就会被当做空数组来处理:$ resty -e 'local cjson = require "cjson" local t = cjson.empty_array print(cjson.encode(t)) ' [] -
cjson.empty_array_mt当它为空的时候编码为数组,它是通过 metatable 的方式进行设置的$ resty -e 'local cjson = require "cjson" local t = {} setmetatable(t, cjson.empty_array_mt) print(cjson.encode(t)) t = {123} print(cjson.encode(t)) ' [] [123]
变量的个数限制
Lua 中,一个函数的局部变量的个数,和 upvalue 的个数都是有上限的,可以从 Lua 的源码中得到印证:
/*
@@ LUAI_MAXVARS is the maximum number of local variables per function
@* (must be smaller than 250).
*/
#define LUAI_MAXVARS 200
/*
@@ LUAI_MAXUPVALUES is the maximum number of upvalues per function
@* (must be smaller than 250).
*/
#define LUAI_MAXUPVALUES 60尽可能地使用 do .. end 做一层封装,来减少局部变量和 upvalue 的个数。
local re_find = ngx.re.find
function foo() ... end
function bar() ... end
function fn() ... end如果只有函数 foo 使用到了 re_find, 那么我们可以这样改造下:
do
local re_find = ngx.re.find
function foo() ... end
end
function bar() ... end
function fn() ... end这样一来,在 main 函数的层面上,就少了 re_find 这个局部变量。这在单个的大的 Lua 文件中,算是一个优化技巧。
Q:当 OpenResty 中的 Lua 规则和 NGINX 配置文件产生冲突时,比如 NGINX 配置了 rewrite 规则,又同时引用了 rewrite_by_lua_file,那么这两条规则的优先级是什么?
location /foo {
rewrite ^ /bar;
rewrite_by_lua 'ngx.exit(503)';
}
location /bar {
...
}在示例代码的这个配置中,ngx.exit(503) 是不会被执行的。
但是,如果你改成下面这样的写法,ngx.exit(503) 就可以被执行。
rewrite ^ /bar break;不过,为了避免这种歧义,我还是建议都使用 OpenResty 来处理 rewrite,而不是 NGINX 的配置。说实话,NGINX 的很多配置是比较晦涩的,需要你反复查阅文档才能读懂。